{kind=link}
The rapid evolution of AI models has driven the need for more efficient and scalable inferencing solutions. As organizations strive to harness the power of AI, they face challenges in deploying, managing, and scaling AI inference workloads. NVIDIA NIM and Google Kubernetes Engine (GKE) together offer a powerful solution to address these challenges. NVIDIA has collaborated with Google Cloud to bring NVIDIA NIM on GKE to accelerate AI inference, providing secure, reliable, and high-performance inferencing at scale with simplified deployment available on Google Cloud Marketplace.
NVIDIA NIM, part of the NVIDIA AI Enterprise software platform available on Google Cloud Marketplace, is a set of easy-to-use microservices designed for secure, reliable deployment of high-performance AI model inferencing. NIM is now integrated with GKE, a managed Kubernetes service that is used to deploy and operate containerized applications at scale using Google Cloud infrastructure.
This post explains how NIM on GKE streamlines the deployment and management of AI inference workloads. This powerful and flexible solution for AI model inferencing leverages the robust capabilities of GKE and the NVIDIA full stack AI platform on Google Cloud.
Easy deployment of performance-optimized inference
The integration of NVIDIA NIM and GKE provides several key benefits for organizations looking to accelerate AI inference:
- Simplified deployment: The one-click deployment feature of NVIDIA NIM on GKE through Google Cloud Marketplace makes it easy to set up and manage AI inference workloads, reducing the time and effort required for deployment.
- Flexible model support: Support for a wide range of AI models, including open-source models, NVIDIA AI foundation models, and custom models, ensures that organizations can use the best models for their specific applications.
- Efficient performance: Built on industry-standard technologies like NVIDIA Triton Inference Server, NVIDIA TensorRT, and PyTorch, the platform delivers high-performance AI inference, enabling organizations to process large volumes of data quickly and efficiently.
- Accelerated computing: Access to a range of NVIDIA GPU instances on Google Cloud—including the NVIDIA H100, A100, and L4—provide a range of accelerated compute options to cover a variety of workloads for a broad set of cost and performance needs.
- Seamless integration: Compatibility with standard APIs and minimal coding requirements enable easy integration of existing AI applications, reducing the need for extensive rework or redevelopment.
- Enterprise-grade features: Security, reliability, and scalability features ensure that AI inference workloads are protected and can handle varying levels of demand without compromising performance.
- Streamlined procurement: Google Cloud Marketplace availability simplifies the acquisition and deployment process, enabling organizations to quickly access and deploy the platform as needed.
Get started with NVIDIA NIM on GKE
To get started leveraging NIM on GKE, follow the steps detailed in this section.
Step 1: Access NVIDIA NIM on GKE in the Google Cloud console and initiate the deployment process. Click the Launch button, and the Deployment details page appears.

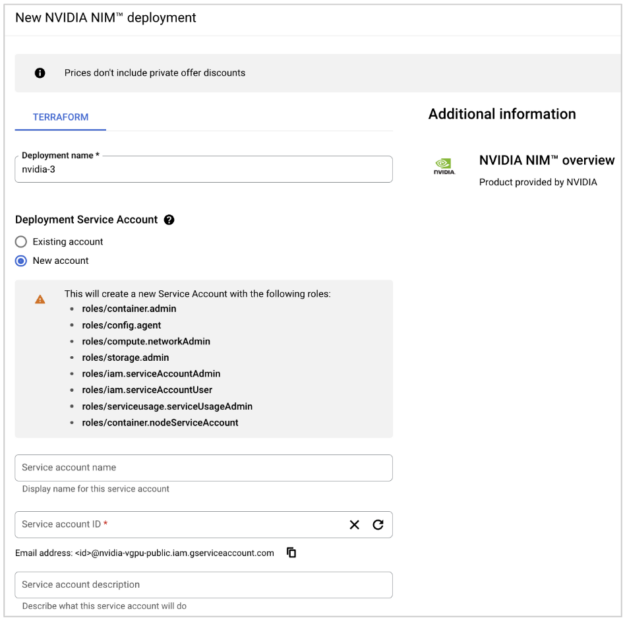
Step 2: Configure the platform to meet specific AI inference requirements, including selecting the desired AI models and setting up deployment parameters. Provide details including a deployment name. You can use an existing Service Account or create a new one.
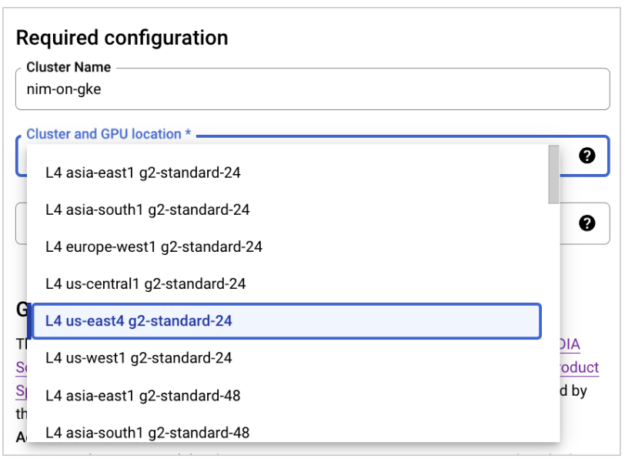
Next, select the appropriate GPU in a specific region corresponding to the instance type from the drop-down menu.
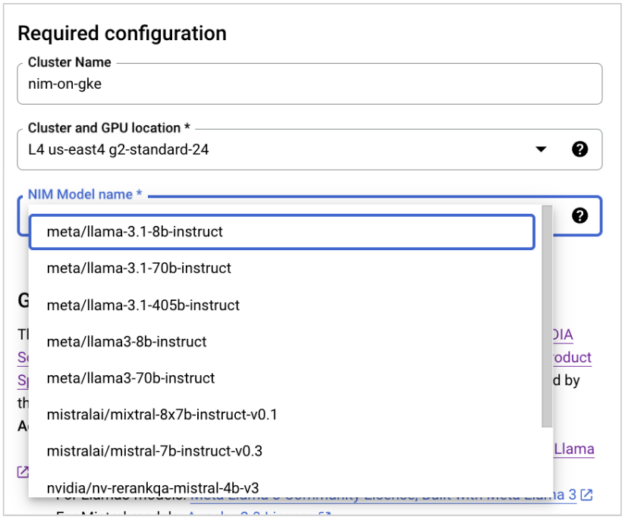
Step 3: Select your NIM from the drop-down menu.
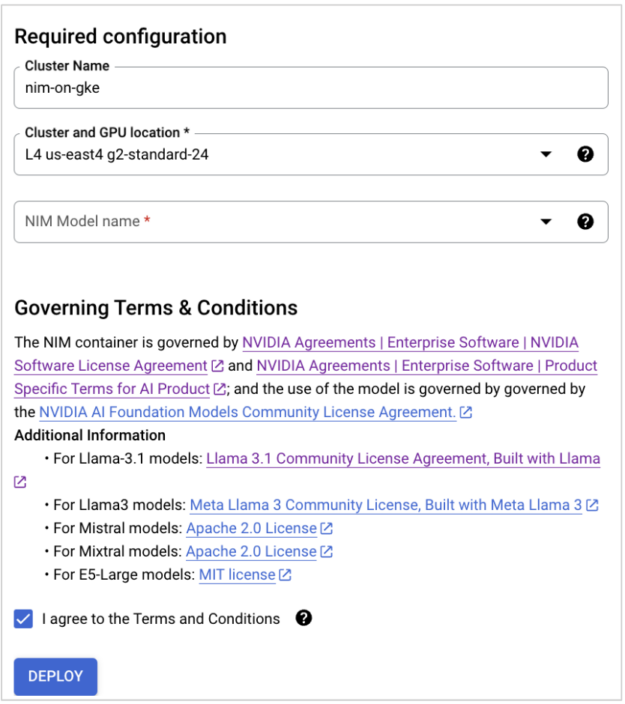
Step 4: Read and accept the EULA, then click Deploy. The deployment takes approximately 15-20 minutes, depending on the NIM and cluster parameters that you choose.
Step 5: Get credentials for the GKE cluster that was created. Navigate to the Google Cloud console to find the new cluster. Then select the Option menu → Connect to grab credentials for it.
gcloud container clusters get-credentials $CLUSTER --region $REGION --project $PROJECT
After the cluster is running, run the inference by setting up port forwarding to the NIM container:
kubectl -n nim port-forward service/my-nim-nim-llm 8000:8000 &
Next, run an inference request against the NIM endpoint using the following curl commands:
curl -X GET 'http://localhost:8000/v1/health/ready'
curl -X GET 'http://localhost:8000/v1/models'
curl -X 'POST' \
'http://localhost:8000/v1/chat/completions' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"content": "You are a polite and respectful chatbot helping people plan a vacation.",
"role": "system"
},
{
"content": "What should I do for a 4 day vacation in Spain?",
"role": "user"
}
],
"model": "meta/llama-3.1-8b-instruct",
"max_tokens": 4096,
"top_p": 1,
"n": 1,
"stream": true,
"stop": "\n",
"frequency_penalty": 0.0
}'
For reranking models, use the following call:
# rerank-qa
curl -X 'POST' \
'http://localhost:8000/v1/ranking' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"query": {"text": "which way should i go?"},
"model": "nvidia/nv-rerankqa-mistral-4b-v3",
"passages": [
{
"text": "two roads diverged in a yellow wood, and sorry i could not travel both and be one traveler, long i stood and looked down one as far as i could to where it bent in the undergrowth;"
},
{
"text": "then took the other, as just as fair, and having perhaps the better claim because it was grassy and wanted wear, though as for that the passing there had worn them really about the same,"
},
{
"text": "and both that morning equally lay in leaves no step had trodden black. oh, i marked the first for another day! yet knowing how way leads on to way i doubted if i should ever come back."
}
]
}'
For embedding models, use the following call:
# embed
curl -X "POST" \
"http://localhost:8000/v1/embeddings" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"input": ["Hello world"],
"model": "nvidia/nv-embedqa-e5-v5",
"input_type": "query"
}'
Ensure that you have the correct URL and the model mentioned under the model parameter.
You can also load test and get performance metrics such as throughput and latency of the deployed model using the NVIDIA GenAI-Perf tool.
Integrate existing AI applications and models with NVIDIA NIM on GKE, leveraging standard APIs and compatibility features to ensure seamless operation. Scale AI inference workloads as needed, using the platform’s scalability features to handle varying levels of demand and optimize resource usage.
Summary
NVIDIA NIM on GKE is a powerful solution for accelerating AI inference, offering ease of use, broad model support, robust foundations, seamless compatibility, and enterprise-grade security, reliability, and scalability. Enterprises can now enhance their AI capabilities, streamline deployment processes, and achieve high-performance AI inferencing at scale. NVIDIA NIM on GKE provides the tools and infrastructure needed to drive innovation and deliver impactful AI solutions. Find NVIDIA NIM on Google Cloud Marketplace.
To learn more, see Efficiently Serve Optimized AI models with NVIDIA NIM Microservices on GKE.