Mobile communication standards play a crucial role in the telecommunications ecosystem by harmonizing technology protocols to facilitate interoperability between networks and devices from different vendors. As these standards evolve, telecommunications companies face the ongoing challenge of managing complexity and volume.
By leveraging generative AI, telecommunications companies can automate the interpretation and application of technical standards. This reduces the time and effort required to navigate through, analyze, and implement rules and protocols from large volumes of specifications. To demonstrate the power of generative AI in processing standards documents, we have developed a chatbot demo for the O-RAN (Open Radio Access Network) standards.
O-RAN provides a set of specifications that aims to promote interoperability, openness, and innovation in the radio access network (RAN) component of telecommunications networks by using open interfaces and modular hardware and software.
This post details our approach, which uses NVIDIA NIM microservices and retrieval-augmented generation (RAG) to efficiently generate responses to complex queries involving large volumes of technical specifications and workflows. This demonstrates the potential of generative AI to transform industry practices and effectively manage complex standards.
O-RAN Chatbot RAG architecture
To deploy the O-RAN chatbot, we used NIM microservices designed for cloud-native, end-to-end RAG applications. Specifically, we used the NVIDIA NeMo Retriever text embedding NIM, NV-Embed-QA-Mistral-7B-v2, to convert passages from O-RAN documentation and user queries into vector representations. Additionally, we implemented a relevance-based NeMo Retriever text reranking NIM to reorder retrieved passages for improved semantic sorting.
To manage data flow and ensure seamless interaction between components, we integrated various chatbot elements using the LangChain framework. We chose a GPU-accelerated FAISS vector database to store embeddings and employed NIM microservices for large language models (LLMs) to generate answers. We implemented a front-end using Streamlit, enabling users to interact directly with the chatbot. Additionally, we deployed NVIDIA NeMo Guardrails to ensure the answers provided were both relevant and factual and further enhance the user experience. Figure 1 illustrates the architecture. To download the code for reference, visit the NVIDIA/GenerativeAIExamples GitHub repo.

Naive RAG challenges
Once we set up the basic RAG architecture without enhancements (Naive RAG), we noticed several issues with the responses. First, the answers provided were often too verbose, and the chatbot’s tone did not align with the intended context. We were able to improve these aspects through appropriate prompt tuning.
Second, we observed that the basic RAG pipeline was unable to retrieve some relevant documents, leading to inaccurate or misleading responses. Additionally, the pipeline struggled to accurately answer the most complex questions, often resulting in partially correct answers or hallucinations.
While prompt tuning successfully addressed tone and verbosity issues, a different approach was needed to handle challenges with retrieval and response accuracy. To tackle these, we first experimented with advanced retrieval strategies and then evaluated different language models. These efforts were aimed at optimizing the bot’s overall quality, which will be detailed in the following sections.
Optimized retrieval strategy
To address the issue of retrieval accuracy, we closely examined queries where the retrieved content was incomplete. We discovered that the problem often arose because relevant parts of the answer were spread across different documents, preventing the retrieval system from accessing all necessary contexts. To tackle this challenge, we explored enhancements to our basic RAG by experimenting with two advanced retrieval methods, Advanced RAG and HyDE, which could potentially improve performance.
Advanced RAG
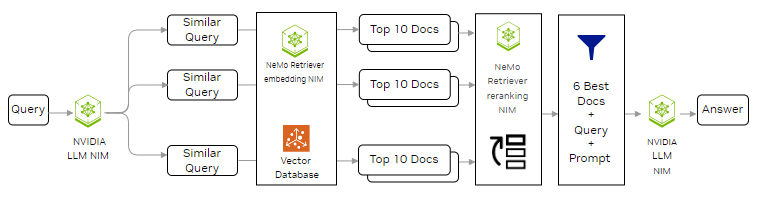
The first enhancement we tried was implementing a query transformation technique, known as Advanced RAG, which uses an LLM to generate multiple subqueries from the initial query. This approach aimed to improve retrieval accuracy by expanding the search space and refining the relevance of the retrieved documents. Figure 2 illustrates the structure of Advanced RAG.
HyDE RAG
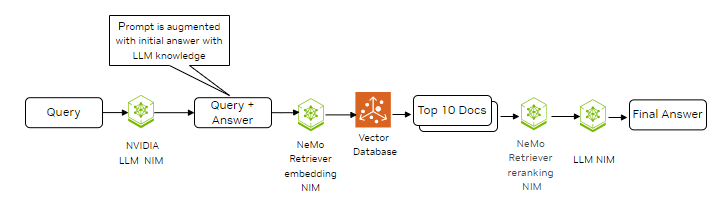
Next, we explored another method called HyDE (Hypothetical Document Embeddings) RAG. HyDE enhances retrieval by considering potential answers, allowing the system to find more contextually relevant documents. This technique had previously outperformed many dense retrievers and demonstrated performance comparable to fine-tuned retrievers across various tasks. Figure 3 provides an overview of how we implemented HyDE RAG and its integration into the retrieval process.
Retriever strategy evaluation
After implementing the Advanced RAG and HyDE RAG techniques, we proceeded to evaluate their performance compared to the basic Naive RAG. Our evaluation combined the insights of human expertise with the efficiency and consistency of automated methods, leveraging the strengths of both approaches.
For the human evaluation, we engaged O-RAN engineers to create 20 questions that covered various aspects of the latest standard release. We then generated answers using all three RAG methodologies: Naive RAG, Advanced RAG, and HyDE RAG. The experts assessed the quality of each response by rating it on a scale of 1 to 5, considering both the overall quality and the relevance of the answer to the question.
For the automated evaluation, we used RAGAs, an open-source framework that employs a state-of-the-art LLM to act as a judge, automating the evaluation process. Figure 4 illustrates our evaluation methodology, showing how both human and automated assessments were integrated to provide a comprehensive comparison of the RAG techniques.
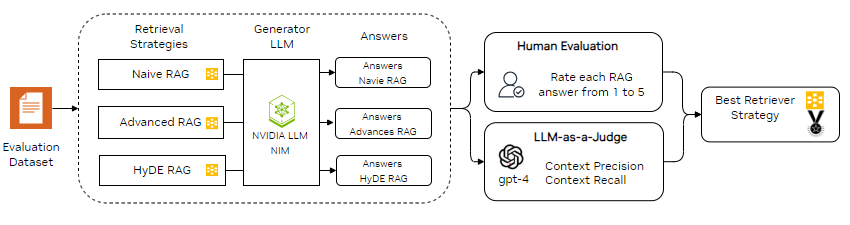
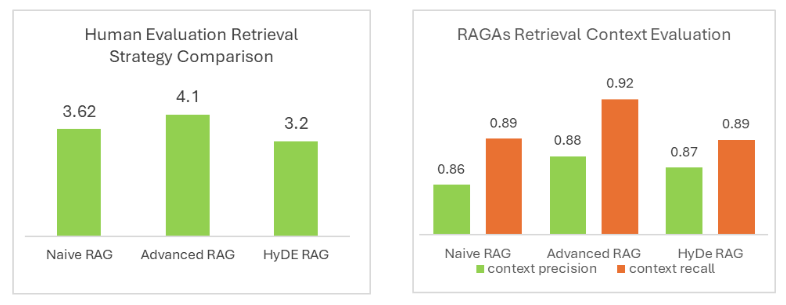
Figure 5 displays the results of these evaluations, clearly showing that using the enhanced RAG techniques led to a noticeable improvement in the quality of the responses. Both human and automated evaluations consistently found that the Advanced RAG method performed better than both the Naive RAG and HyDE RAG methods.
Selection of NVIDIA LLM NIM
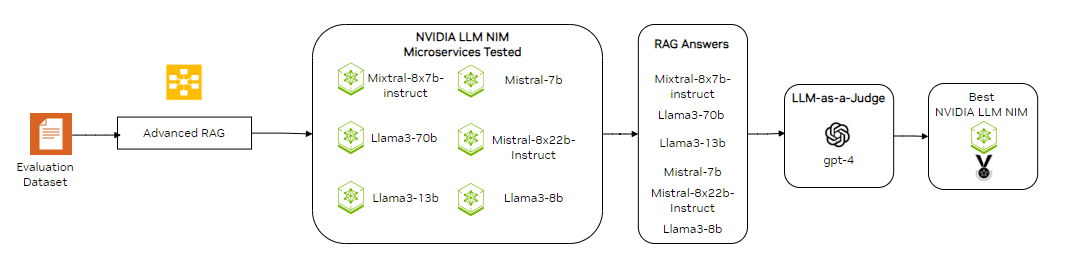
After identifying the best retriever strategy, we aimed to further improve answer accuracy by evaluating different LLM NIM microservices. As shown in the workflow below, we experimented with various models to determine the most accurate one. Using the Advanced RAG pipeline, we generated answers with different LLM NIM microservices and assessed their performance. To do this, we employed the RAGAs framework using LLM-as-a-Judge to calculate two key metrics: faithfulness and answer relevancy.
Given the large number of NIM microservices we needed to compare, we opted to prioritize automated evaluation over human evaluation, which would have been time-consuming and required significant engineering resources. Figure 6 illustrates our LLM NIM evaluation process.
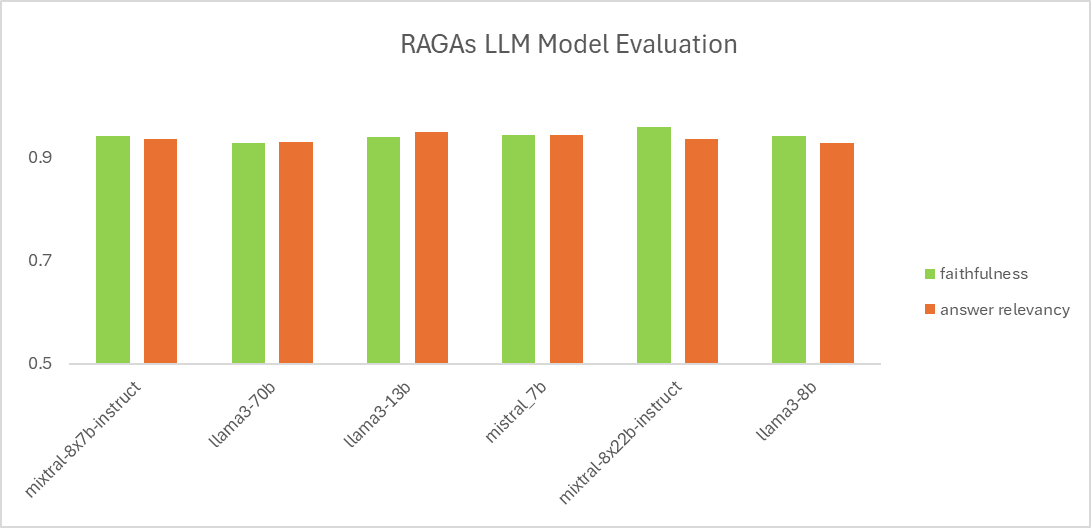
Based on the results in Figure 7, we noticed that all the LLMs performed at par, showing little performance difference between them. This suggested that retrieval optimization was the key factor. Once refined, it enabled all the open-source LLMs to achieve comparable performance.
Conclusion
We demonstrated the value of building advanced RAG pipelines to create an expert chatbot capable of understanding O-RAN technical specifications by utilizing NVIDIA LLM NIM microservices and NeMo Retriever embedding and reranking NIM microservices. By leveraging open-source LLMs enhanced with advanced retrieval techniques, we significantly improved the accuracy of responses to complex technical questions.
Our evaluation framework showed that the Advanced RAG method consistently outperformed other methodologies in both retrieval accuracy and overall response quality. The success of the O-RAN chatbot highlights that integrating the NVIDIA end-to-end platform for developing custom generative AI enables telecommunications companies to improve their efficiency in processing technical standards, thereby maintaining a competitive edge in the rapidly evolving telecommunications industry.
To learn more, visit the NVIDIA/GenerativeAIExamples GitHub repo.