Introduction
The era has arrived where your phone or computer can understand the objects of an image, thanks to technologies like YOLO and SAM.
Meta’s Segment Anything Model (SAM) can instantly identify objects in images and separate them without needing to be trained on specific images. It’s like a digital magician, able to understand each object in an image with just a wave of its virtual wand. After the successful release of llama 3.1, Meta announced SAM 2 on July 29th, a unified model for real-time object segmentation in images and videos, which has achieved state-of-the-art performance.
SAM 2 offers numerous real-world applications. For instance, its outputs can be integrated with generative video models to create innovative video effects and unlock new creative possibilities. Additionally, SAM 2 can enhance visual data annotation tools, speeding up the development of more advanced computer vision systems.

What is Image Segmentation in SAM?
Segment Anything (SAM) introduces an image segmentation task where a segmentation mask is generated from an input prompt, such as a bounding box or point indicating the object of interest. Trained on the SA-1B dataset, SAM supports zero-shot segmentation with flexible prompting, making it suitable for various applications. Recent advancements have improved SAM’s quality and efficiency. HQ-SAM enhances output quality using a High-Quality output token and training on fine-grained masks. Efforts to increase efficiency for broader real-world use include EfficientSAM, MobileSAM, and FastSAM. SAM’s success has led to its application in fields like medical imaging, remote sensing, motion segmentation, and camouflaged object detection.
Dataset Used
Many datasets have been developed to support the video object segmentation (VOS) task. Early datasets feature high-quality annotations but are too small for training deep learning models. YouTube-VOS, the first large-scale VOS dataset, covers 94 object categories across 4,000 videos. As algorithms improved and benchmark performance plateaued, researchers increased the VOS task difficulty by focusing on occlusions, long videos, extreme transformations, and both object and scene diversity. Current video segmentation datasets lack the breadth needed to ” segment anything in videos,” as their annotations typically cover entire objects within specific classes like people, vehicles, and animals. In contrast, the recently introduced SA-V dataset focuses not only on whole objects but also extensively on object parts, containing over an order of magnitude more masks. The SA-V dataset collected comprises of 50.9K videos with 642.6K masklets.

Model Architecture
The model extends SAM to work with both videos and images. SAM 2 can use point, box, and mask prompts on individual frames to define the spatial extent of the object to be segmented throughout the video. When processing images, the model operates similarly to SAM. A lightweight, promptable mask decoder takes a frame’s embedding and any prompts to generate a segmentation mask. Prompts can be added iteratively to refine the masks.
Unlike SAM, the frame embedding used by the SAM 2 decoder isn’t taken directly from the image encoder. Instead, it’s conditioned on memories of past predictions and prompts from previous frames, including those from “future” frames relative to the current one. The memory encoder creates these memories based on the current prediction and stores them in a memory bank for future use. The memory attention operation uses the per-frame embedding from the image encoder and conditions it on the memory bank to produce an embedding that is passed to the mask decoder.
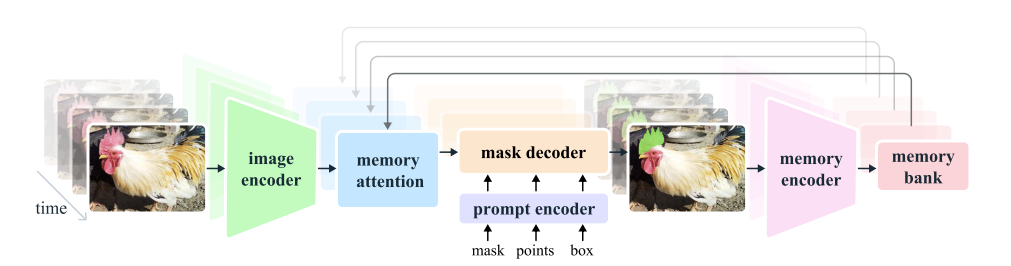
Here’s a simplified explanation of the different components and processes present in the image:
Image Encoder
- Purpose: The image encoder processes each video frame to create feature embeddings, which are essentially condensed representations of the visual information in each frame.
- How It Works: It runs only once for the entire video, making it efficient. MAE and Hiera extracts features at different levels of detail to help with accurate segmentation.
Memory Attention
- Purpose: Memory attention helps the model use information from previous frames and any new prompts to improve the current frame’s segmentation.
- How It Works: It uses a series of transformer blocks to process the current frame’s features, compare them with memories of past frames, and update the segmentation based on both. This helps handle complex scenarios where objects might move or change over time.
Prompt Encoder and Mask Decoder
- Prompt Encoder: Similar to SAM’s, it takes input prompts (like clicks or boxes) to define what part of the frame to segment. It uses these prompts to refine the segmentation.
- Mask Decoder: It works with the prompt encoder to generate accurate masks. If a prompt is unclear, it predicts multiple possible masks and selects the best one based on overlap with the object.
Memory Encoder and Memory Bank
- Memory Encoder: This component creates memories of past frames by summarizing and combining information from previous masks and the current frame. This helps the model remember and use information from earlier in the video.
- Memory Bank: It stores memories of past frames and prompts. This includes a queue of recent frames and prompts and high-level object information. It helps the model keep track of object changes and movements over time.
Training
- Purpose: The model is trained to handle interactive prompting and segmentation tasks using both images and videos.
- How It Works: During training, the model learns to predict segmentation masks by interacting with sequences of frames. It receives prompts like ground-truth masks, clicks, or bounding boxes to guide its predictions. This helps the model become good at responding to various types of input and improving its segmentation accuracy.
Overall, the model is designed to efficiently handle long videos, remember information from past frames, and accurately segment objects based on interactive prompts.
SAM 2 Performance


SAM 2 significantly outperforms previous methods in interactive video segmentation, achieving superior results across 17 zero-shot video datasets and requiring about three times fewer human interactions. It surpasses SAM in its zero-shot benchmark suite by being six times faster and excels in established video object segmentation benchmarks like DAVIS, MOSE, LVOS, and YouTube-VOS. With real-time inference at approximately 44 frames per second, SAM 2 is 8.4 times faster than manual per-frame annotation with SAM.
How to install SAM 2?
Bring this project to life
To start the installation, open up a Paperspace Notebook and start the GPU machine of your choice.
# Clone the repo
!git clone https://github.com/facebookresearch/segment-anything-2.git
# Move to the folder
cd segment-anything-2
# Install the necessary requirements
!pip install -e .To use the SAM 2 predictor and run the example notebooks, jupyter and matplotlib are required and can be installed by:
pip install -e ".[demo]"Download the checkpoints
cd checkpoints
./download_ckpts.shHow to use SAM 2?
Image prediction
SAM 2 can be used for static images to segment objects. SAM 2 offers image prediction APIs similar to SAM for these use cases. The SAM2ImagePredictor class provides a user-friendly interface for image prompting.
import torch
from sam2.build_sam import build_sam2
from sam2.sam2_image_predictor import SAM2ImagePredictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = SAM2ImagePredictor(build_sam2(model_cfg, checkpoint))
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)Video prediction
SAM 2 supports video predictor as well on multiple objects and also uses an inference state to keep track of the interactions in each video.
import torch
from sam2.build_sam import build_sam2_video_predictor
checkpoint = "./checkpoints/sam2_hiera_large.pt"
model_cfg = "sam2_hiera_l.yaml"
predictor = build_sam2_video_predictor(model_cfg, checkpoint)
with torch.inference_mode(), torch.autocast("cuda", dtype=torch.bfloat16):
state = predictor.init_state(<your_video>)
# add new prompts and instantly get the output on the same frame
frame_idx, object_ids, masks = predictor.add_new_points(state, <your prompts>):
# propagate the prompts to get masklets throughout the video
for frame_idx, object_ids, masks in predictor.propagate_in_video(state):
...In the video we have used SAM 2 to segment the coffee mug
Summary
- SAM 2 Overview: SAM 2 builds on SAM by extending its capabilities from images to videos. It uses prompts like clicks, bounding boxes, or masks to define object boundaries in each frame. A lightweight mask decoder processes these prompts and generates segmentation masks for each frame.
- Video Processing: In videos, SAM 2 applies the initial mask prediction across all frames to create a masklet. It allows for iterative refinement by adding prompts to subsequent frames.
- Memory Mechanism: For video segmentation, SAM 2 uses a memory encoder, memory bank, and memory attention module. The memory encoder stores frame information and user interactions, enabling accurate predictions across frames. The memory bank holds data from previous and prompted frames, which the memory attention module uses to refine predictions.
- Streaming Architecture: SAM 2 processes frames one at a time in a streaming fashion, making it efficient for long videos and real-time applications like robotics. It uses the memory attention module to incorporate past frame data into current predictions.
- Handling Ambiguity: SAM 2 addresses ambiguity by generating multiple masks when prompts are unclear. If prompts do not resolve the ambiguity, the model selects the mask with the highest confidence for further use throughout the video.
SAM 2 Limitations
- Performance and Improvement: While SAM 2 performs well in segmenting objects in images and short videos, its performance can be enhanced, especially in challenging scenarios.
- Challenges in Tracking: SAM 2 may struggle with drastic changes in camera viewpoints, long occlusions, crowded scenes, or lengthy videos. To address this, the model is designed to be interactive, allowing users to manually correct tracking with clicks on any frame to recover the target object.
- Object Confusion: When the target object is specified in only one frame, SAM 2 might confuse it with similar objects. Additional refinement prompts in future frames can resolve these issues, ensuring the correct masklet is maintained throughout the video.
- Multiple Object Segmentation: Although SAM 2 can segment multiple objects simultaneously, its efficiency decreases significantly because each object is processed separately using only shared per-frame embeddings. Incorporating shared object-level context could improve efficiency.
- Fast-Moving Objects: For complex, fast-moving objects, SAM 2 might miss fine details, leading to unstable predictions across frames, as shown with the cyclist example. While adding prompts can partially remove this, predictions may still lack temporal smoothness since the model isn’t penalized for oscillation between frames.
- Data Annotation and Automation: Despite advances in automatic masklet generation using SAM 2, human annotators are still needed for verifying quality and identifying frames that need correction. Future improvements could further automate the data annotation process to boost efficiency.