{kind=link}
Microsoft Bing Visual Search enables people around the world to find content using photographs as queries. The heart of this capability is Microsoft’s TuringMM visual embedding model that maps images and text into a shared high-dimensional space. Operating on billions of images across the web, performance is critical.
This post details efforts to optimize the TuringMM pipeline using NVIDIA TensorRT and NVIDIA acceleration libraries like CV-CUDA and nvImageCodec. These efforts resulted in a 5.13x speedup and significant TCO reduction. We share how we worked with the Microsoft Bing team to tackle optimization of their core embeddings pipelines that power internet-scale visual search.
According to Andrew Stewart, PhD and senior data and applied scientist with Microsoft Bing Multimedia, “The Bing Visual Search team achieved a remarkable 5.13x end-to-end throughput improvement for an offline indexing pipeline running on billions of images using NVIDIA acceleration technology including TensorRT, CV-CUDA, and nvImageCodec, resulting in significant energy and cost savings. For online systems, like Visual Intent from Bing, such improvements mean quicker results for users, or the ability to incorporate additional functionality within the expected latency budget.”
Multimodal AI and visual search
Multimodal AI powers applications such as visual search. Multimodal AI applications require fusing different data modalities such as text, photo, audio, and video, so that they can interact with one another seamlessly. One popular model for joint image-text understanding is CLIP (Contrastive Language-Image Pretraining). CLIP models employ a dual encoder architecture, one for images and one for text, that consumes hundreds of millions of image-caption pairs.
The output of each encoder is aligned in a shared high-dimensional space to produce a single high-dimensional vector or an embedding that represents the joint semantic understanding of the input text and image pair. These multimodal embeddings are used to power a wide range of AI-based vision tasks like text-based visual search and retrieval, zero-shot image classification, image captioning and labeling, text-input based content creation/editing, text-assisted content moderation and many more.
Microsoft Bing Visual Search
Microsoft Bing Visual Search requires computing large-scale vector embeddings for billions of images. Running such an offline system in the cloud or data center can take several weeks to even months to populate the embeddings database. In such cases, where multiple workloads could be running on a shared cluster and resource constraints exist, effective utilization of compute resources and reduction in time taken to complete each workload becomes critical.
On the other hand, for online tasks like visual search or image captioning, real-time responsiveness through reduced end-to-end latency for each request is a high-priority requirement.
Model and pipeline prior to optimizations
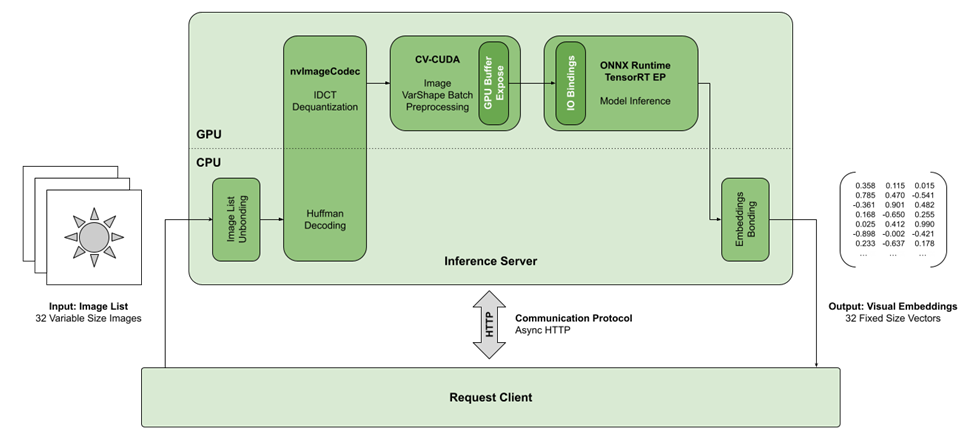
The visual embeddings model, as with many other models in the Bing infrastructure, runs on a GPU server cluster dedicated to executing inference tasks for a variety of Microsoft’s deep learning services. Within this cluster, the model executes inside an inference server solution on each instance. The inference server receives a batch of images to process from the centralized job dispatcher, and is expected to send back the predicted embeddings for each of these images.
The workload consists of periodically processing all new images posted to the World Wide Web since the last index. The images to be processed are assembled in request batches of 32 images each, and these batches are sent to the GPU inference servers to be processed. As these images have been collected from the internet from a wide variety of sources, they will vary in size and file format. It is therefore up to the inference task to reformat the images on each batch into a homogenous data layout so that they can be processed in parallel by the model.
Image processing at this scale is a computationally expensive process. The work starts with reading and decoding the images. The images are in large part found in JPEG format, but they may also include a variety of other common file formats. In addition, image sizes range from small thumbnails to the large professional graphics and high-resolution smartphone photos. The images in the request batch must then all be resized to a common resolution matching the model’s expected input shape of 224×224.
Furthermore, some basic image preprocessing is applied to the image, consisting of cropping, normalization, and reordering of channels and tensor layout. To deal with the complexity of this wide variety of image specifications, OpenCV was originally chosen to load and process these images.
The main inference task consists of executing the visual embeddings model on this preprocessed input batch. The model is exported as an ONNX graph and ONNXRuntime is used as the model execution backend. The ONNXRuntime framework provides a unified set of operations to provide execution compatibility for any model that can be expressed with a standard ONNX opset. The framework provides multiple Execution Providers, which are basically the implementation for each of these operations for a specific hardware platform or accelerator. The default Execution Provider is for CPU execution.
There are different ways to accelerate ONNX graphs with GPUs. First, ONNX graphs can be run using NVIDIA TensorRT directly. Second, ONNXRuntime provides two Execution Providers powered by NVIDIA:
- CUDA Execution Provider: Offers a general-purpose GPU acceleration solution that provides good performance and flexibility. It is suitable for a wide range of models that conform to the ONNX specification. Bing’s original implementation used ONNXRuntime with CUDA Execution Provider.
- TensorRT Execution Provider: Offers maximum performance and efficiency for deep learning inference on NVIDIA GPUs by leveraging advanced optimizations like reduced precision and layer fusion. It is ideal for deployment scenarios where performance, throughput, and low latency are critical.

Optimizing the visual embeddings model pipeline
We collaborated with the Microsoft Bing Visual Search team to find optimization opportunities in this pipeline. Several possibilities immediately become apparent as providing beneficial performance upside by making better use of the GPU resources.
The first and obvious opportunity was with the use of TensorRT. Recent versions of TensorRT have added ever-improving support for fused attention layers in transformer architectures. This enables more efficient execution of these computationally expensive layers, which significantly impacts the end-to-end inference performance.
Decoding the JPEG file format is not often given much thought. However, when dealing with models at scale that have been largely optimized, the loading and decoding of a single megapixel image can often be longer than the inference task itself for that image. Bing’s visual embeddings pipeline was no exception to this, as we could measure significant bottlenecks originating from OpenCV’s imread call, the function that implements image format decoding.
To alleviate this, we introduced to the pipeline nvImageCodec, the NVIDIA library of image format decoders. This library makes use of GPUs to decode a large variety of file formats. When a dedicated hardware-accelerated decoder is not available, the library transparently falls back to traditional software GPU-accelerated decoding, and if that is not available either, to CPU-accelerated decoding.
This enables maintaining compatibility and seamless integration across formats, which is essential when dealing with raw image data collected from the internet. Finally, nvImageCodec also supports batch decoding, which enables decoding multiple images simultaneously so some key operations can be parallelized during the decoding stage. This maximizes GPU efficiency.
The preprocessing of the images themselves was also accelerated with CV-CUDA, the NVIDIA library for the GPU-accelerated implementation of common image processing operations. These operations have been highly optimized to work with image batches: the larger the number of images to process, the greater will be the efficiency of these operations.
Some of the CV-CUDA operations support variable shape image batches. This means that although images may not all conform to a single image size, they can still be batched together and the batch parallelization can be exploited on such collections. Furthermore, the integration of CV-CUDA with nvImageCodec, enables processing the image data directly on GPU buffers, avoiding the need to copy the data back and forth to the host CPU.
The final implementation was largely simplified due to the Python bindings available in both libraries. The Python APIs for both nvImageCodec and CV-CUDA follow the same conventions and function names as the OpenCV API, for users that may already be familiar with it. The code for these operations is as follows:
decoder = nvimgcodec.Decoder
images = decoder.decode(batch_queries)
images_batch = cvcuda.ImageBatchVarShape(len(images))
for image in images:
images_batch.pushback(cvcuda.as_image(image))
images_batch = cvcuda.resize(images_batch, [(256, 256)] * len(images), cvcuda.Interp.LINEAR)
stack = cvcuda.stack([cvcuda.as_tensor(image) for image in images_batch])
stack = cvcuda.customcrop(stack, cvcuda.RectI(16, 16, 224, 224))
stack = cvcuda.cvtcolor(stack, cvcuda.ColorConversion.RGB2BGR)
stack = cvcuda.convertto(stack, np.float32)
stack = cvcuda.reformat(stack, "NCHW")
stack = stack.cuda
Finally, ONNXRuntime has the ability to use IOBindings. This is a feature in the framework that allows pre-allocating and filling memory buffers on the target accelerator directly. In the case of ONNXRuntime-CUDA and ONNXRuntime-TensorRT, this enables providing the model’s input batch data directly to a pre-allocated GPU memory buffer, again avoiding the need for additional memory copies between the CPU and GPU.
The optimized pipeline fully offloads the majority of the inference task to the GPU device, allowing for more optimal and faster processing, but also for greater power efficiency for the end-to-end task.
Results
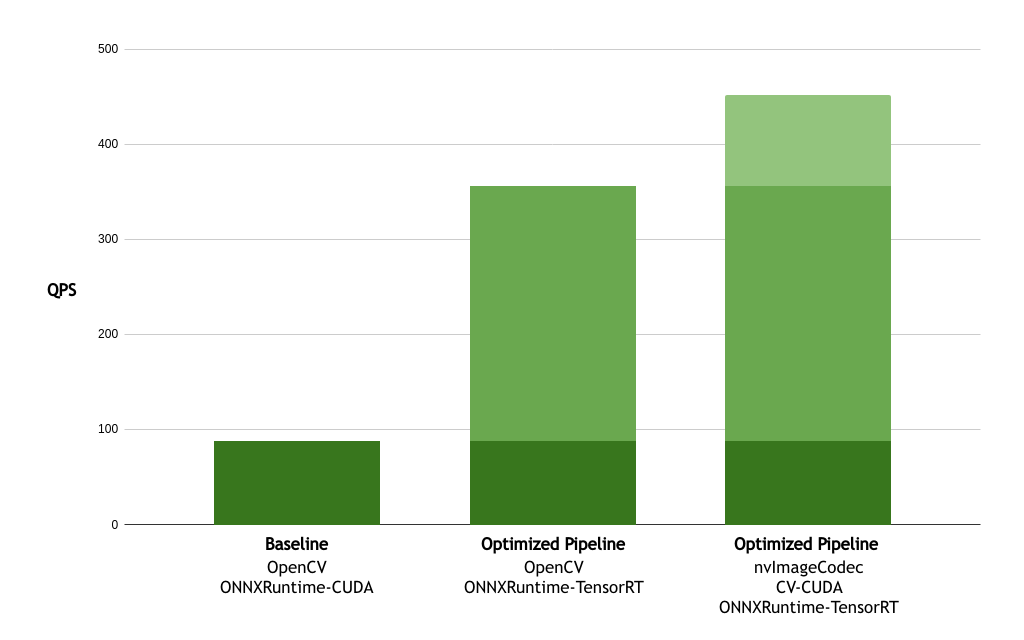
The results obtained show how optimal use of GPU resources can largely accelerate deep learning and image processing workloads, even when the baseline is already using GPU acceleration. NVIDIA TensorRT was responsible for most of the performance improvement, and NVIDIA image decoding and processing libraries were ultimately responsible for an additional 27% end-to-end improvement.
| Implementation | Throughput | Speedup |
| Baseline using OpenCV + ONNXRuntime-CUDA | 88 QPS | – |
| Pipeline using OpenCV + ONNXRuntime-TensorRT | 356 QPS | 4.05 |
| Pipeline using nvImageCodec + CV-CUDA + ONNXRuntime-TensorRT | 452 QPS | 5.14 |
The image processing component of the pipeline contributes considerable latency to the end-to-end inference request. The fact that images of different sizes are used in such inference tasks often results in variable latency numbers, as the time to decode and resize images is proportional to image resolution. Accelerating this process can provide significant performance improvements, resulting in up to 6x speedups, using hardware specifications such as those used in the deployment by Bing.
| Average image size per batch | ||||
| Library | Process | Small (~400×400) |
Medium (~800×800) |
Large (~1600×1600) |
| OpenCV Single-threaded CPU |
Image decode | 28.4 ms | 162.3 ms | 406.2 ms |
| Preprocessing | 6.3 ms | 14.4 ms | 24.0 ms | |
| Total | 34.7 ms | 176.7 ms | 430.2 ms | |
| nvImageCodec + CV-CUDA GPU-accelerated |
Image decode | 5.9 ms | 29.4 ms | 62.7 ms |
| Preprocessing | 3.2 ms | 5.2 ms | 6.3 ms | |
| Total | 9.1 ms | 34.6 ms | 69.0 ms | |
| GPU acceleration speedup | 3.8x | 5.1x | 6.2x | |
Conclusion
NVIDIA accelerated libraries, including TensorRT, CV-CUDA, and nvImageCodec, significantly optimized Microsoft Bing Visual Search. The pipeline’s initial implementation used ONNXRuntime with CUDA for GPU acceleration, but bottlenecks in image decoding and preprocessing (through OpenCV) limited performance. NVIDIA accelerated libraries were introduced to improve both image decoding and model inference speeds.
The introduction of TensorRT, nvImageCodec for decoding, and CV-CUDA for image preprocessing resulted in the 5.13x speedup. These improvements reduced the image processing time by up to 6.2x in some cases. These optimizations enhanced the system’s throughput and allowed Bing to process visual search tasks more efficiently, reducing energy usage and processing times significantly.
NV-CLIP is an NVIDIA commercial version of the CLIP model available as an NVIDIA NIM microservice. NIM microservices provide models as optimized containers to deploy in the cloud, data centers, workstations, desktops, and laptops. Each NIM container includes the pretrained AI models and all the necessary runtime components, making it simple to integrate AI capabilities into applications. Get started with NV-CLIP.