{kind=link}
Developers have shown a lot of excitement for NVIDIA NIM microservices, a set of easy-to-use cloud-native microservices that shortens the time-to-market and simplifies the deployment of generative AI models anywhere, across cloud, data centers, cloud, and GPU-accelerated workstations.
To meet the demands of diverse use cases, NVIDIA is bringing to market a variety of different AI models packaged as NVIDIA NIM microservices, which enable key functionality in a generative AI inference workflow.
A typical generative AI application integrates multiple different NIM microservices. For instance, multi-turn conversational AI in a RAG pipeline uses the LLM, embedding, and re-ranking NIM microservices. The deployment and lifecycle management of these microservices and their dependencies for production generative AI pipelines can lead to additional toil for the MLOps and LLMOps engineers and Kubernetes cluster admins.
This is why NVIDIA is announcing the NVIDIA NIM Operator, a Kubernetes operator designed to facilitate the deployment, scaling, monitoring, and management of NVIDIA NIM microservices on Kubernetes clusters. With NIM Operator, you can deploy, auto-scale, and manage the lifecycle of NVIDIA NIM microservices with just a few clicks or commands.
Cluster admins and MLOps and LLMOps engineers don’t have to put effort into the manual deployment, scaling, and lifecycle management of AI inference pipelines. NIM Operator handles all of this and more.
Core capabilities and benefits
Developers are looking to reduce the effort of deploying AI inference pipelines at scale in local deployments. NIM Operator facilitates this with simplified, lightweight deployment and manages the lifecycle of AI NIM inference pipelines on Kubernetes. NIM Operator also supports pre-caching models to enable faster initial inference and autoscaling.


Figure 2. NIM Operator Helm deployment
Intelligent model pre-caching
NIM Operator offers pre-caching of models that reduces initial inference latency and enables faster autoscaling. It also enables model deployments in air-gapped environments.
Use NIM intelligent model pre-caching by specifying NIM profiles and tags, or let NIM Operator auto-detect the best model based on the GPUs available on the Kubernetes cluster. You can pre-cache models on any available node based on your requirements, either on CPU-only or on GPU-accelerated nodes.
When this option is selected, NIM Operator creates a persistent volume claim (PVC) in Kubernetes and then downloads and caches the NIM models in the cluster. Then, NIM Operator deploys and manages the lifecycle of this PVC using the NIMCache custom resource.

Figure 3. NIM microservice cache deployment
Automated AI NIM pipeline deployments
NVIDIA is introducing two Kubernetes custom resource definitions (CRDs) to deploy NVIDIA NIM microservices: NIMService and NIMPipeline.
NIMService, when deployed, manages each NIM microservice as a standalone microservice.NIMPipelineenables the deployment and management of several NIM microservices collectively.
Figure 4 shows a RAG pipeline managed as a microservice pipeline. You can manage multiple pipelines as a collection instead of individual services.
Figure 4. NIM microservice pipeline deployment
Autoscaling
NIM Operator supports auto-scaling the NIMService deployment and its ReplicaSet using Kubernetes Horizontal Pod Autoscaler (HPA).
The NIMService and NIMPipeline CRDs support all the familiar HPA metrics and scaling behaviors, such as the following:
- Specify minimum and maximum replica counts
- Scale using the following metrics:
- Per-pod resource metrics, such as CPU
- Per-pod custom metrics, such as GPU memory usage
- Object metrics, such as NIM max requests or
KVCache - External metrics
You can also specify any HPA scale-up and scale-down behavior, for example, a stabilization window to prevent flapping and scaling policies to control the rate of change of replicas while scaling.
For more information, see GPU Metrics.
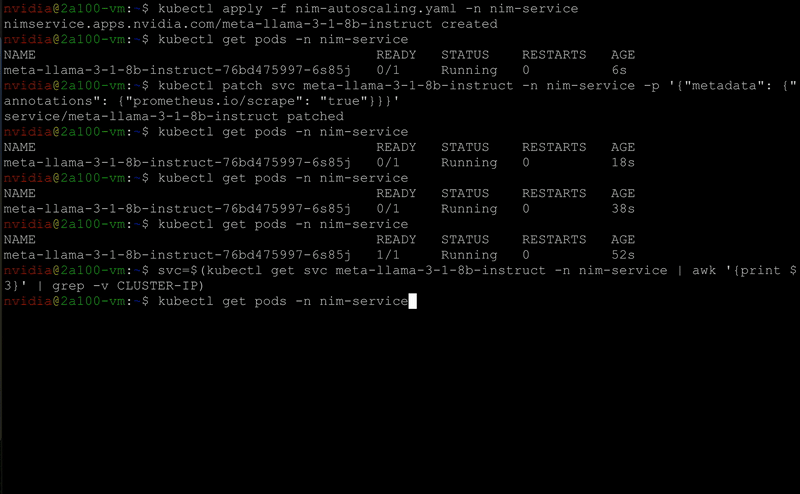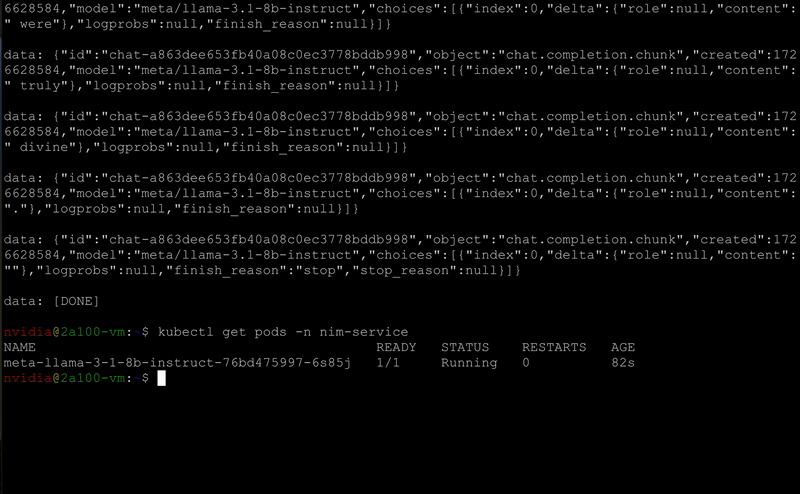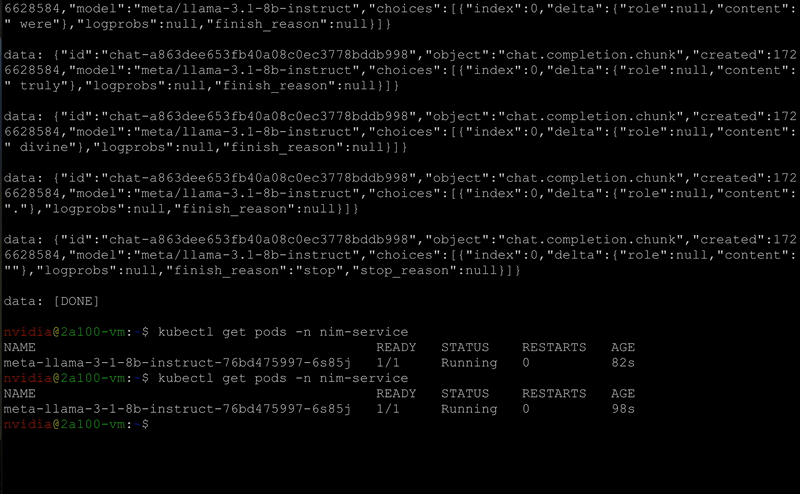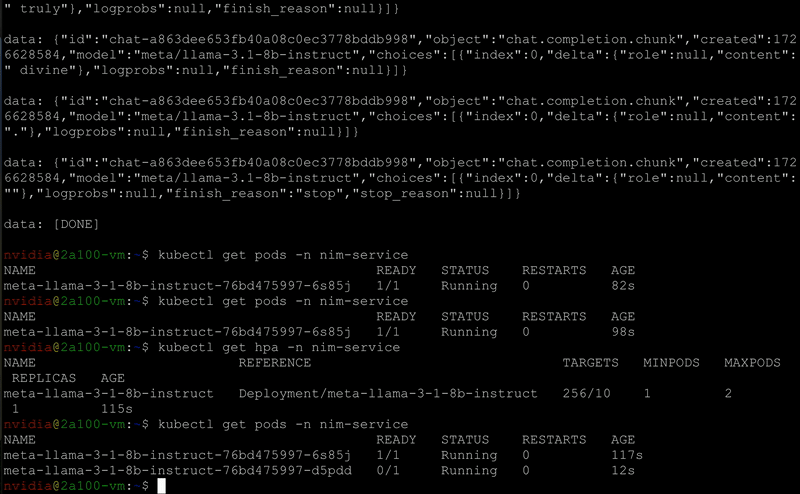
Figure 5. NIM Auto-scaling
Day 2 operations
NIMService and NIMPipeline support easy rolling upgrades of NIM with a customizable rolling strategy. Change the version number of the NIM in the NIMService or NIMPipeline CRD and NIM Operator updates the NIM deployments in the cluster.
Any changes in NIMService pods are reflected in the NIMService and NIMPipeline status. You can also add Kubernetes ingress for NIMService.
Support matrix
At launch, NIM Operator supports the reasoning LLM and the retrieval—embedding NIM microservice.
We are continuously expanding the list of supported NVIDIA NIM microservices. For more information about the full list of supported NIM microservices, see Platform Support.
Conclusion
By automating the deployment, scaling, and lifecycle management of NVIDIA NIM microservices, NIM Operator makes it easier for enterprise teams to adopt NIM microservices and accelerate AI adoption.
This effort aligns with our commitment to make NIM microservices easy to adopt, production-ready, and secure. NIM Operator will be part of future releases of NVIDIA AI Enterprise to provide enterprise support, API stability, and proactive security patching.
Get started with NIM Operator through NGC today, or get it from the GitHub repo. For technical questions on installation, usage, or issues, please file an issue on the repo.