Today, NVIDIA released a unique language model that delivers an unmatched accuracy-efficiency performance. Llama 3.1-Nemotron-51B, derived from Meta’s Llama-3.1-70B, uses a novel neural architecture search (NAS) approach that results in a highly accurate and efficient model.
The model fits on a single NVIDIA H100 GPU at high workloads, making it much more accessible and affordable. The excellent accuracy-efficiency sweet spot exhibited by the new model stems from changes to the model’s architecture that lead to a significantly lower memory footprint, reduced memory bandwidth, and reduced FLOPs while maintaining excellent accuracy. We demonstrate that this approach can be generalized by creating another smaller and faster variant from the reference model.
In July 2024, Meta released Llama-3.1-70B, a leading state-of-the-art large language model (LLM). Today we announce Llama 3.1-Nemotron-51B-Instruct, developed using NAS and knowledge distillation derived from the reference model, Llama-3.1-70B.
Superior throughput and workload efficiency
The Nemotron model yields 2.2x faster inference compared to the reference model while maintaining nearly the same accuracy. The model opens a new set of opportunities with a reduced memory footprint, which enables running 4x larger workloads on a single GPU during inference.
| Accuracy | Efficiency | |||
| MT Bench | MMLU | Text generation (128/1024) | Summarization/ RAG (2048/128) | |
| Llama-3.1- Nemotron-51B- Instruct | 8.99 | 80.2% | 6472 | 653 |
| Llama 3.1-70B- Instruct | 8.93 | 81.66% | 2975 | 339 |
| Llama 3.1-70B- Instruct (single GPU) | — | — | 1274 | 301 |
| Llama 3-70B | 8.94 | 80.17% | 2975 | 339 |
Note: Speed is reported in tokens per second per GPU, Measured on machines equipped with 8 X NVIDIA H100 SXM GPUs, with FP8 quantization using TRT-LLM as the runtime engine. For each model with the optimal number of GPUs through tensor parallelism (unless otherwise stated). The numbers in the brackets show the (input/output sequence lengths).
We discuss the detailed performance metrics later in this post.
Optimized accuracy per dollar
Foundation models display incredible quality in solving complex tasks: reasoning, summarization, and more. However, a major challenge in the adoption of top models is their inference cost.
As the field of generative AI evolves, the balance between accuracy and efficiency (directly impacting cost) will become the decisive factor in model selection. Moreover, the capability to run a model on a single GPU significantly streamlines its deployment, opening opportunities for new applications to run anywhere, from edge systems to data centers to the cloud, as well as facilitating serving multiple models via Kubernetes and NIM blueprints.
Consequently, we engineered Llama 3.1-Nemotron-51B-Instruct to achieve this optimal tradeoff (Figure 1). Throughput is inversely proportional to price, so the best tradeoff is obtained by models on the efficient frontier displayed in the chart. Figure 1 shows that the model pushes beyond the current efficient frontier, making it the model that provides the best accuracy per dollar.

The model quality is defined as the weighted average of MT-Bench and MMLU (10*MT-Bench + MMLU)/2, plotted compared to model throughput per a single NVIDIA H100 80GB GPU. Gray dots represent state-of-the-art models, while the dashed line represents the ‘efficient frontier’.
Simplifying inference with NVIDIA NIM
The Nemotron model is optimized with TensorRT-LLM engines for higher inference performance and packaged as an NVIDIA NIM microservice to streamline and accelerate the deployment of generative AI models across NVIDIA accelerated infrastructure anywhere, including cloud, data center, and workstations.
NIM uses inference optimization engines, industry-standard APIs, and prebuilt containers to provide high-throughput AI inference that scales with demand.
Try out Llama-3.1-Nemotron-51B NIM microservice through the API from ai.nvidia.com with free NVIDIA credits.
Building the model with NAS
Inference and hardware-aware methods for designing neural architectures have been successfully used in many domains. However, LLMs are still constructed as repeated identical blocks, with little regard for inference cost overheads incurred by this simplification. To tackle these challenges, we developed efficient NAS technology and training methods that can be used to create non-standard transformer models designed for efficient inference on specific GPUs.
Our technology can select neural architectures that optimize various constraints. The range includes enormous design spaces that include a zoo of non-standard transformer models using alternative attention and FFN blocks of varying efficiency degrees, up to a complete block elimination in the extreme case.
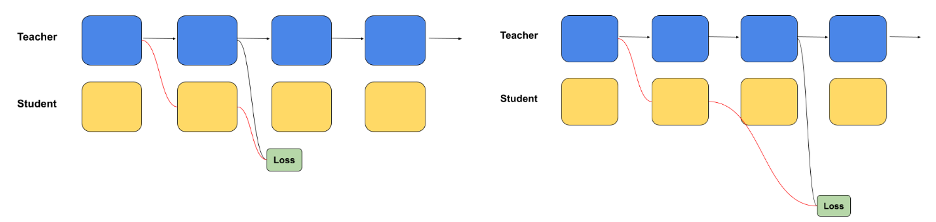
We then use our block-distillation (Figure 2) framework to train all these block variants for all layers of a (large) parent LLM in parallel. In a basic version of block-distillation, training data is passed through the reference model (also known as a teacher).
For each block, its input is taken from the teacher and injected into the matching block of the student. The outputs of the teacher and student for the block are compared and the student block is trained so that the student block mimics the functionality of the teacher block. A more advanced scenario where a single student block mimics multiple teacher blocks is depicted on the right side in Figure 2.
Next, we use our Puzzle algorithm to efficiently score each alternative replacement puzzle piece and search our enormous design space for the most accurate models, while adhering to a set of inference constraints, such as memory size and required throughput.
Finally, by using knowledge distillation (KD) loss for both block scoring and training, we demonstrate the potential to narrow the accuracy gap between our model and the reference model using a much more efficient architecture with a tiny fraction of the reference model training costs. Using our methods on Llama-3.1-70B as the reference model, we built Llama-3.1-Nemotron-51B-Instruct, a 51B model that breaks the efficient frontier of LLMs on a single NVIDIA H100 GPU (Figure 1).
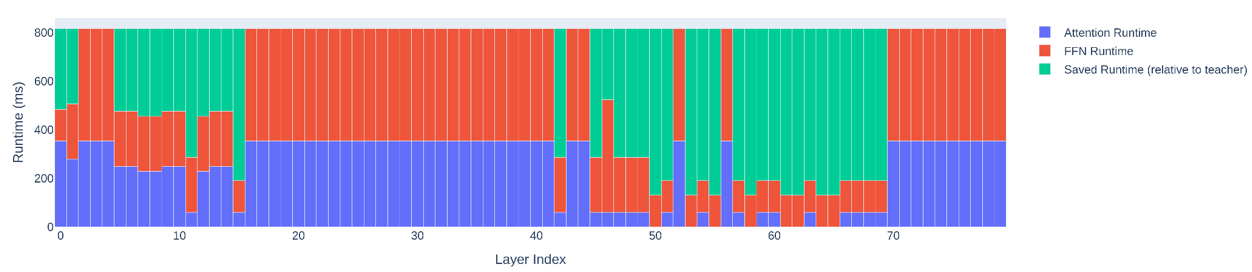
The Llama-3.1-Nemotron-51B-Instruct architecture is unique in its irregular block structure with many layers in which the attention and FFN are reduced or pruned, resulting in better utilization of H100 and highlighting the importance of optimizing LLMs for inference. Figure 3 schematically depicts the irregular structure of the resulting architecture and highlights the resulting compute saving, which amounts to the green area in the Figure.
Our innovative techniques enable us to develop models that redefine the efficient frontier of LLMs. Crucially, we can cost-effectively design multiple models from a single reference model, each optimized for specific hardware and inference scenarios. This capability empowers us to maintain best-in-class performance for LLM inference across our current and future hardware platforms.
Detailed results
Here are the model accuracy and performance metrics for our model.
Model accuracy
Table 2 lists all the benchmarks that we evaluated, comparing our model and the reference model Llama-3.1-70B. The Accuracy preserved column is the ratio between our model’s score and that of the teacher.
| Benchmark | Llama-3.1 70B-instruct | Llama-3.1-Nemotron-51B- Instruct | Accuracy preserved |
| winogrande | 85.08% | 84.53% | 99.35% |
| arc_challenge | 70.39% | 69.20% | 98.30% |
| MMLU | 81.66% | 80.20% | 98.21% |
| hellaswag | 86.44% | 85.58% | 99.01% |
| gsm8k | 92.04% | 91.43% | 99.34% |
| truthfulqa | 59.86% | 58.63% | 97.94% |
| xlsum_english | 33.86% | 31.61% | 93.36% |
| MMLU Chat | 81.76% | 80.58% | 98.55% |
| gsm8k Chat | 81.58% | 81.88% | 100.37% |
| Instruct HumanEval (n=20) | 75.85% | 73.84% | 97.35% |
| MT Bench | 8.93 | 8.99 | 100.67% |
Performance
Table 3 shows the number of tokens per second per GPU (NVIDIA H100 80-GB GPU). You can see that for a range of relevant scenarios, short and long inputs as well as outputs, our model doubles the throughput of the teacher model, making it cost-effective across multiple use cases.
TPX describes the number of GPUs on which the process runs in parallel. We also list the performance of Llama 3.1-70B on a single GPU to demonstrate the value of our model in such a setting.
| Scenario | Input/Output Sequence Length | Llama-3.1- Nemotron-Instruct | Llama-3.1-70B-Instruct | Ratio | Llama (TP1) |
| Chatbot | 128/128 | 5478 (TP1) | 2645 (TP1) | 2.07 | 2645 |
| Text generation | 128/1024 | 6472 (TP1) | 2975 (TP4) | 2.17 | 1274 |
| Long text generation | 128/2048 | 4910 (TP2) | 2786 (TP4) | 1.76 | 646 |
| System 2 reasoning | 128/4096 | 3855 (TP2) | 1828 (TP4) | 2.11 | 313 |
| Summarization/ RAG | 2048/128 | 653 (TP1) | 339 (TP4) | 1.92 | 300 |
| Stress test 1 | 2048/2048 | 2622 (TP2) | 1336 (TP4) | 1.96 | 319 |
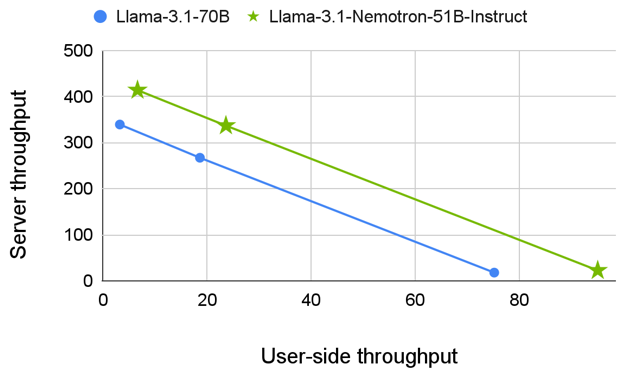
The main factor in determining the cost of running a model is throughput, the total number of tokens that the system can generate in one second. However, in some scenarios (for example, chatbots), the rate at which a single end user receives the response from the model is important for the user experience. This is quantified by the tokens per second per user, termed the user-side throughput.
Figure 4 shows this user-side throughput plotted against the throughput at different batch sizes. As seen in all batch sizes, our model is superior to Llama-3.1-70B.
Tailoring LLMs for diverse needs
The NAS approach offers you flexibility in selecting the optimal balance between accuracy and efficiency. To demonstrate this versatility, we created another variant from the same reference model, this time prioritizing speed and cost. Llama-3.1-Nemotron-40B-Instruct was developed using the same methodology but with a modified speed requirement during the puzzle phase.
This model achieves a 3.2x speed increase compared to the parent model, with a moderate decrease in accuracy. Table 4 shows competitive performance metrics.
| Accuracy | Speed | |||
| MT bench | MMLU | Text generation (128/1024) | Summarization/ RAG (2048/128) | |
| Llama-3.1- Nemotron-40B-Instruct | 8.69 | 77.10% | 9568 | 862 |
| Llama-3.1- Nemotron-51B-Instruct | 8.99 | 80.20% | 6472 | 653 |
| Llama 3.1-70B-Instruct | 8.93 | 81.72% | 2975 | 339 |
Summary
Llama 3.1-Nemotron-51B-Instruct provides a new set of opportunities for users and companies that want to use highly accurate foundation models, but do so in a cost-controlled manner. By providing the best tradeoff between accuracy and efficiency, we believe the model is an attractive option for builders. Moreover, these results demonstrate the effectiveness of the NAS approach and intend to extend the method to other models.