{kind=link}
NVIDIA NIM, part of NVIDIA AI Enterprise, provides containers to self-host GPU-accelerated inferencing microservices for pretrained and customized AI models across clouds, data centers, and workstations. NIM microservices for speech and translation are now available.
The new speech and translation microservices leverage NVIDIA Riva and provide automatic speech recognition (ASR), neural machine translation (NMT), and text-to-speech (TTS) services.
Integrating multilingual voice capabilities into your applications with NVIDIA speech and translation NIM microservices offers beyond just advanced ASR, NMT, and TTS for enhanced global user experience and accessibility. Whether you’re building customer service bots, interactive voice assistants, or multilingual content platforms, these NIM microservices are optimized for high-performance AI inference at scale, and provide accuracy and flexibility to voice-enable your applications with minimal development effort.
In this post, you’ll learn how to perform basic inference tasks—such as transcribing speech, translating text, and generating synthetic voices—directly through your browser by using interactive speech and translation model interfaces in the NVIDIA API catalog. You’ll also learn how to run these flexible microservices on your infrastructure, access them through APIs, and seamlessly integrate them into your applications.
Quick inference with speech and translation NIM
Speech NIM microservices are available in the API catalog, where you can easily perform inference tasks using the interactive browser UI. With the click of a button, you can transcribe English speech, translate text between over 30 languages, or convert text into natural-sounding speech. The API catalog provides a convenient starting point for exploring the basic capabilities of speech and translation NIM microservices.
The true power of these tools lies in their flexibility to be deployed wherever your data resides—anywhere. You can run these microservices on any compatible NVIDIA GPU, access them through APIs, and seamlessly integrate them into your applications. This versatility enables you to deploy speech NIM microservices in environments ranging from local workstations to cloud and data center infrastructure, providing scalable options tailored to your needs.
Running speech and translation NIM microservices with NVIDIA Riva Python clients
This section guides you through cloning the nvidia-riva / python-clients GitHub repo and using provided scripts to run simple inference tasks on the NVIDIA API catalog Riva endpoint, located at grpc.nvcf.nvidia.com:443.
To quickly test the speech NIM microservices, navigate to a NIM landing page from the API catalog and click the Try API tab. Note that to use these commands, you’ll need an NVIDIA API key. If you don’t already have one, simply click the Get API Key button in the far right corner under the Try API tab. Read on for some examples of what you can do.
Transcribing audio in streaming mode
Run the following command to transcribe an audio file in real time.
python python-clients/scripts/asr/transcribe_file.py \
--server grpc.nvcf.nvidia.com:443 --use-ssl \
--metadata function-id "1598d209-5e27-4d3c-8079-4751568b1081" \
--metadata "authorization" "Bearer
$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC" \
--language-code en-US \
--input-file <path_to_audio_file>
Translating text from English to German
The following command translates the English sentence, “This is an example text for Riva text translation” into German, “Dies ist ein Beispieltext für Riva Textübersetzung.”
python python-clients/scripts/nmt/nmt.py \
--server grpc.nvcf.nvidia.com:443 --use-ssl \
--metadata function-id "647147c1-9c23-496c-8304-2e29e7574510" \
--metadata "authorization" "Bearer
$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC" \
--text "This is an example text for Riva text translation" \
--source-language-code en \
--target-language-code de
Generating synthetic speech
The following command converts the text, “This audio is generated from NVIDIA’s text-to-speech model” into speech and saves the audio output as audio.wav. This is particularly useful if you’re working in a terminal on a remote system and the audio output cannot easily be routed to your local microphone.
python python-clients/scripts/tts/talk.py \
--server grpc.nvcf.nvidia.com:443 --use-ssl \
--metadata function-id "0149dedb-2be8-4195-b9a0-e57e0e14f972" \
--metadata authorization "Bearer
$API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC" \
--text "this audio is generated from nvidia's text-to-speech model" \
--voice "English-US.Female-1" \
--output audio.wav
Running speech NIM locally with Docker
If you have access to advanced NVIDIA data center GPUs, you can run the speech NIM microservices locally by following the instructions provided under the Docker tabs of the ASR, NMT, and TTS NIM landing pages. Alternatively, you can refer to the more detailed Getting Started documentation for ASR, NMT, and TTS that explains each docker run parameter and guides you through the setup process.
An NGC API key is required to pull NIM microservices from the NVIDIA container registry (nvcr.io) and run them on your own system. The NVIDIA API key that you generated in the previous section should work for this purpose. Alternatively, navigate to an ASR, NMT, or TTS NIM landing page, select the Docker tab, and click on Get API Key.
Integrating speech NIM microservices with a RAG pipeline
This section covers launching the ASR and TTS NIM microservices on your system and connecting them to a basic retrieval-augmented generation (RAG) pipeline from the NVIDIA Generative AI Examples GitHub repo. This setup enables uploading documents into a knowledge base, asking questions about them verbally, and obtaining answers in synthesized, natural-sounding voices.
Set up the environment
Before launching the NIM microservices, export your NGC API key to your system as NGC_API_KEY, either directly in the terminal or through your environmental source file.
Next, log into the NVIDIA Docker container registry:
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken'
--password-stdin
Then, create a LOCAL_NIM_CACHE directory:
export LOCAL_NIM_CACHE=<path/to/nim_cache>
mkdir -p "$LOCAL_NIM_CACHE"
chmod 777 $LOCAL_NIM_CACHE
You’ll store your models in this directory and mount it to the NIM containers. Make sure not to skip the chmod 777 command. Otherwise, the NIM Docker container will lack permission to download the model files to the LOCAL_NIM_CACHE directory.
By default, the speech NIM microservices download the model files to a location that’s only accessible inside a running container. If you intend to run only one of the Riva services at a time, you should either leave LOCAL_NIM_CACHE unspecified, clear your LOCAL_NIM_CACHE directory between stopping one NIM container and starting another one, or specify a different LOCAL_NIM_CACHE directory for each speech NIM. Here the same LOCAL_NIM_CACHE is used for both ASR and TTS so as to run both services simultaneously.
Launch the ASR NIM
Use the following script to start the ASR NIM:
export CONTAINER_NAME=parakeet-ctc-1.1b-asr
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus '"device=0"' \
--shm-size=8GB \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_MANIFEST_PROFILE=9136dd64-4777-11ef-9f27-37cfd56fa6ee \
-e NIM_HTTP_API_PORT=9000 \
-e NIM_GRPC_API_PORT=50051 \
-p 9000:9000 \
-p 50051:50051 \
-v "$LOCAL_NIM_CACHE:/home/nvs/.cache/nim" \
nvcr.io/nim/nvidia/parakeet-ctc-1.1b-asr:1.0.0
If the LOCAL_NIM_CACHE directory is empty (such as the first time you execute this command), it may take 20-30 minutes to complete. During this time, NIM will download the acoustic (offline, streaming optimized for latency, and streaming optimized for throughput) and punctuation models as .tar.gz files, then uncompress them within the container.
You might want to change the NIM_MANIFEST_PROFILE parameter, depending on your GPU type. By default, the NIM container downloads ONNX-formatted model files that run on any sufficiently advanced NVIDIA GPU. However, if you change this parameter appropriately when starting the ASR or TTS NIM, you’ll instead download NVIDIA TensorRT-formatted model files that have been optimized for NVIDIA H100, A100, or L40 GPUs. This results in faster inference on one of the supported GPUs. Optimized NIM support for additional GPU types is forthcoming.
Table 1 shows the supported NIM_MANIFEST_PROFILE values for the ASR NIM for the Parakeet CTC Riva 1.1B En-US model:
| GPU | NIM_MANIFEST_PROFILE |
| Generic | 9136dd64-4777-11ef-9f27-37cfd56fa6ee |
| NVIDIA H100 | 7f0287aa-35d0-11ef-9bba-57fc54315ba3 |
| NVIDIA A100 | 32397eba-43f4-11ef-b63c-1b565d7d9a02 |
| NVIDIA L40 | 40d7e326-43f4-11ef-87a2-239b5c506ca7 |
NIM_MANIFEST_PROFILE values for the ASR NIM for the Parakeet CTC Riva 1.1B En-US modelYou can also find this table in the Supported Models section of the Getting Started page in the ASR NIM documentation. Note the slight difference between the model name and the container name. Unlike some other NIM microservices, the speech and translation NIM microservices do not support the list-model-profiles utility, meaning you can’t access the list of valid NIM_MANIFEST_PROFILE values through the docker CLI.
Launch the TTS NIM
After stopping the ASR NIM, either with Ctrl+C in the same terminal or with docker stop or docker container stop in a different terminal, launch the TTS NIM:
export CONTAINER_NAME=fastpitch-hifigan-tts
docker run -it --rm --name=$CONTAINER_NAME \
--runtime=nvidia \
--gpus '"device=0"' \
--shm-size=8GB \
-e NGC_API_KEY=$NGC_API_KEY \
-e NIM_MANIFEST_PROFILE=3c8ee3ee-477f-11ef-aa12-1b4e6406fad5 \
-e NIM_HTTP_API_PORT=9000 \
-e NIM_GRPC_API_PORT=50051 \
-p 9000:9000 \
-p 50051:50051 \
-v "$LOCAL_NIM_CACHE:/home/nvs/.cache/nim" \
nvcr.io/nim/nvidia/fastpitch-hifigan-tts:1.0.0
From Table 2, choose a suitable NIM_MANIFEST_PROFILE value for the FastPitch HifiGAN Riva En-US model:
| GPU | NIM_MANIFEST_PROFILE |
| Generic | 3c8ee3ee-477f-11ef-aa12-1b4e6406fad5 |
| NVIDIA H100 | bbce2a3a-4337-11ef-84fe-e7f5af9cc9af |
| NVIDIA A100 | 5ae1da8e-43f3-11ef-9505-e752a24fdc67 |
| NVIDIA L40 | 713858f8-43f3-11ef-86ee-4f6374fce1aa |
You can also find this table in the Supported Models section of the Getting Started page in the TTS NIM documentation. Note the slight difference between the model name and the container name.
Starting the TTS NIM should be much faster than starting the ASR NIM, because the constituent models take up far less space in total. However, because we’re using the same LOCAL_NIM_CACHE directory for both the ASR and TTS NIMs, the TTS NIM will launch both the ASR and TTS models.
Connect the speech NIM microservices to the RAG pipeline
The RAG web app is part of the NVIDIA Generative AI Examples GitHub repo. After cloning the repo, the main thing you need to do is edit RAG/examples/basic_rag/langchain/docker-compose.yaml. Set the PLAYGROUND_MODE for the rag-playground service to speech and add the following environment variables to that service:
services:
...
rag-playground:
...
environment:
...
RIVA_API_URI: <riva-ip-address>:50051
TTS_SAMPLE_RATE: 48000
If you wish to set RIVA_API_URI with an overridable default value in the docker-compose file (in the format shown below), do not put quotation marks around the default value. If you do, the Python os module will include them in the string defining the Riva URI, which will cause problems.
RIVA_API_URI: ${RIVA_API_URI:-<riva-ip-address>:50051}
Even if you’re running the RAG example and the speech NIM microservices on the same machine, you need to specify the IP address or permanent hostname; localhost won’t work here.
See more detailed instructions on adding ASR and TTS capabilities to a RAG pipeline in the Generative AI Examples repo.
Once the docker-compose file is edited appropriately, run the following command in the same directory to start the container network.
docker compose up -d --build
Also verify that each container within the network is running:
docker ps --format "table {{.ID}}\t{{.Names}}\t{{.Status}}"
Test the speech NIM and RAG integration
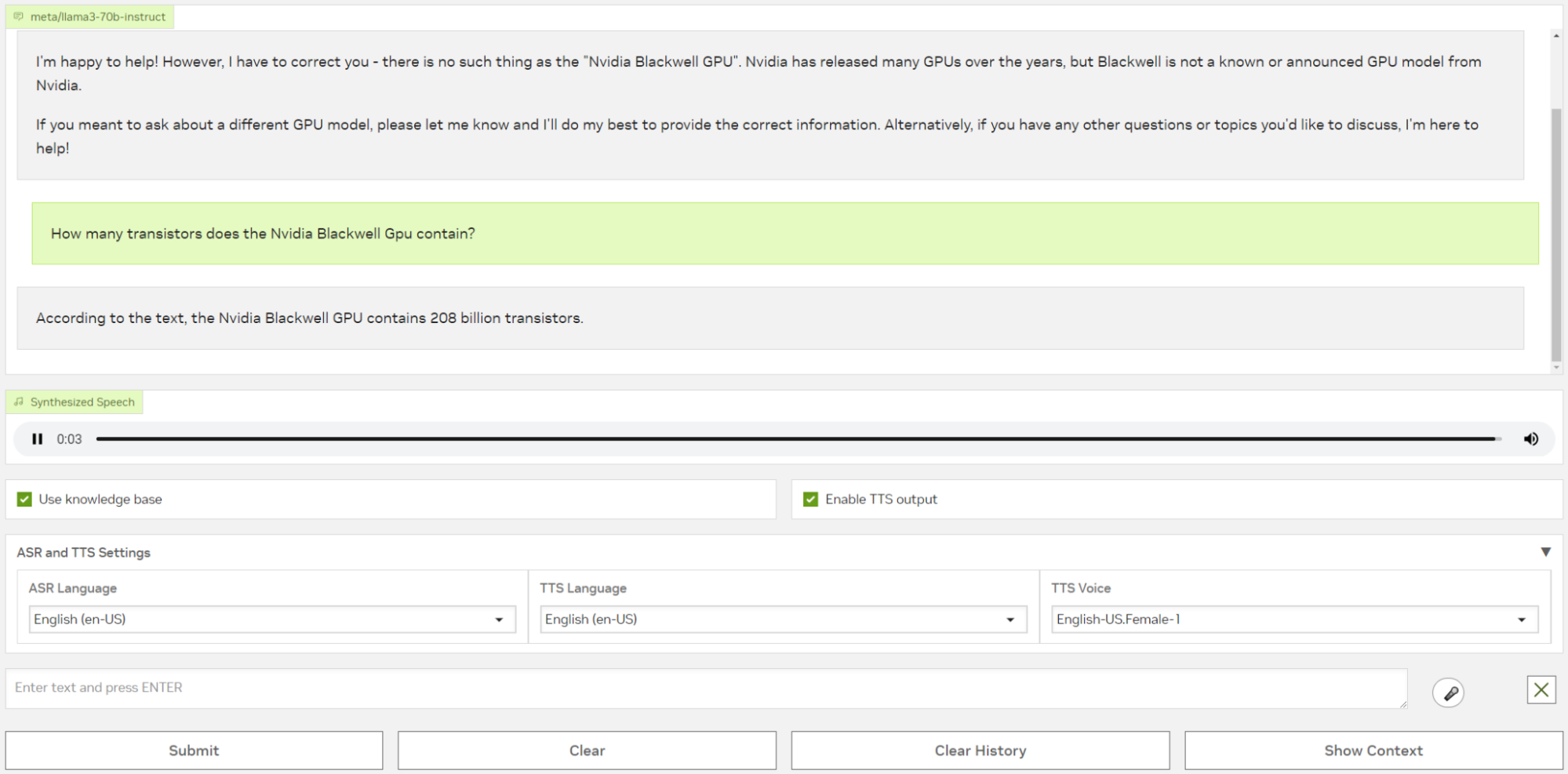
To test your setup, navigate to localhost:8090 in your browser. If you’re running the RAG app on a remote system without port forwarding, use <remote-IP-address>:8090 instead. The interface (Figures 1 and 2) enables you to query the large language model (LLM) by text or voice, and receive a spoken response. If the models are available, you can change the ASR and TTS languages using menu options.
For document-based queries, click on the Knowledge Base tab near the top right of the page. Here, you can upload PDF, plain text, or markdown files. The contents are embedded as multidimensional vectors and indexed in a vector database, enabling the LLM to answer questions based on this new information.
To provide an example, upload a PDF version of the recent press release, NVIDIA Blackwell Platform Arrives to Power a New Era of Computing. Despite being published over five months ago, the default LLM for this sample web app is not pretrained of this information.
Next, return to the Converse tab, click the microphone button, and ask the app, “How many transistors does the NVIDIA Blackwell GPU contain?” Without the knowledge base, the LLM is unable to provide the correct answer (Figure 1).

Now, with the knowledge base active, ask the same question again. This time, leveraging the full RAG pipeline, the LLM answers correctly based on the newly embedded information (Figure 2).
Get started adding multilingual speech AI to your apps
In this post, you’ve learned to set up NVIDIA speech and translation NIM microservices and test them directly through your browser by using the interactive speech and translation model interfaces. You have dived into the flexibility of deploying NIM speech and translation microservices and integrating them into a RAG pipeline for document-based knowledge retrieval with synthesized voice responses.
Ready to add powerful multilingual speech AI to your own applications? Try speech NIM microservices to experience the ease of integrating ASR, NMT, and TTS into your pipelines. Explore the APIs and see how these NIM microservices can transform your applications to scalable, real-time voice services for worldwide users.