{kind=link}
The continued growth of LLMs capability, fueled by increasing parameter counts and support for longer contexts, has led to their usage in a wide variety of applications, each with diverse deployment requirements. For example, a chatbot supports a small number of users at very low latencies for good interactivity. Meanwhile, synthetic data generation requires high throughput to process many items at once. Delivering optimal inference performance across a wide range of use cases with one platform requires optimization across the entire technology stack.
Cutting-edge LLMs, like Llama 3.1 405B, require multiple GPUs working together for peak performance. To effectively use multiple GPUs for processing inference requests, an inference software stack must provide developers with optimized implementations of key parallelism techniques, including tensor, pipeline, and expert parallelism. These parallelism techniques require that GPUs be able to transfer data quickly and efficiently, necessitating a robust GPU-to-GPU interconnect fabric for maximum performance.
In this post, we explain two of these parallelism techniques and show, on an NVIDIA HGX H200 system with NVLink and NVSwitch, how the right parallelism increases Llama 3.1 405B performance by 1.5x in throughput-sensitive scenarios. We also show how use of pipeline parallelism enabled a 1.2x speedup in the MLPerf Inference v4.1 Llama 2 70B benchmark on HGX H100 compared to our results published in August. These improvements are possible due to recent software improvements in TensorRT-LLM with NVSwitch.
Choosing parallelism for deployment
Both tensor parallel (TP) and pipeline parallel (PP) techniques increase compute and memory capacity by splitting models across multiple GPUs, but they differ in how they impact performance. Pipeline parallelism is a low-overhead mechanism for efficiently increasing overall throughput, while tensor parallelism is a higher-overhead mechanism for reducing latency. In some scenarios, TP can also increase throughput proportional to a single GPU. More details on these techniques are in the following sections.
To illustrate the trade-offs between tensor and pipeline parallelism, we investigate the Llama 2 and Llama 3.1 family of models in two scenarios: minimum latency for peak interactivity, and maximum throughput for peak efficiency. This comparison focuses on total output tokens per second, which is representative of interactivity at small concurrencies (minimum latency) and efficiency at large concurrencies (maximum throughput).
| Llama 3.1 405B Output Tokens/second (higher is better) |
Parallelism | ||
| Tensor | Pipeline | ||
| Scenario | minimum latency | 56 | 10 |
| maximum throughput | 506 | 764 | |
NVIDIA H200 HGX | Measured on internal TensorRT-LLM based on v0.14a | FP8 PTQ | 2048:128 | Minimum latency: Concurrency 1 | Maximum throughput: maximum concurrency fit in memory
In the table above, tensor parallelism is compared to pipeline parallelism with each across eight GPUs on Llama 3.1 405B, the largest and most capable open source LLM available today. In the minimum latency scenario, TP allows for more available GPU compute to generate each token, leading to 5.6x faster performance than pipeline parallelism. However, for maximum throughput, pipeline parallelism can improve maximum system throughput by 1.5x by reducing overhead and leveraging the additional bandwidth available with NVLink Switch.
Pipeline parallelism delivers 1.2x boost on MLPerf on H100
The TensorRT-LLM software improvements also benefit smaller models. When the recent pipeline parallelism improvements in TensorRT-LLM were applied to MLPerf Llama 2 70B scenario, throughput on an HGX H100 8-GPU system increased by 21% compared to our MLPerf Inference v4.1 results published in August.
| MLPerf Inference Output Tokens/second (higher is better) |
Parallelism | ||
| Tensor Parallelism | Pipeline Parallelism | ||
| Scenario | Llama 2 70B | 24,525 | 29,741 |
Results obtained for the available category of Closed Division, on OpenORCAdataset using NVIDIA H100 Tensor Core GPU, official numbers from 4.1-0043 submission used for Tensor Parallelism, Pipeline parallelism based on scripts provided in submission ID- 4.1-0043 and TensorRT-LLM version 0.12.0.
Result not verified by MLCommons Association. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use is strictly prohibited. See www.mlcommons.org for more information.
Tensor and pipeline parallelism are both valuable techniques. Individually, they are suitable for different use cases, however, developers can combine them in various ways to optimize inference throughput within a given interactivity target. We will dive into how to find this balance in a future blog.
Tensor and pipeline parallelism explained
Tensor parallelism (TP) splits the execution of each model layer across multiple GPUs. Every calculation is distributed across available GPUs, and each GPU performs its own portion of the calculation. Then, every GPU broadcasts its individual results, known as partial sums, to every other GPU using an AllReduce operation. This process generates substantial data traffic between the GPUs.

Pipeline parallelism (PP) operates by splitting groups of model layers – or stages – across available GPUs. A request will begin on one GPU and will continue execution across subsequent stages on subsequent GPUs. With PP, communication only occurs between adjacent stages, rather than between all GPUs like with TP execution. While communication is less frequent, very high-bandwidth communication between stages is critical to ensure that execution does not stall, degrading performance.
For minimum latency use cases, the communication traffic generated during tensor parallel execution does not saturate available interconnect bandwidth. This means that multiple GPUs can work in tandem to generate each token, increasing interactivity. Meanwhile, with pipeline parallel execution, a request can only utilize the GPU compute available within a given stage. This means that compute per token does not increase with additional GPUs with pipeline parallelism.
For scenarios where high throughput is required, the all-to-all communication pattern of TP can become a bottleneck, hindering performance. If link bandwidth is fixed regardless of the number of available connections, then in high-throughput use cases PP can improve throughput somewhat, as communication overhead is reduced, however, execution can still be link limited. With a high-bandwidth interconnect like NVLink with NVSwitch, communication overhead can be minimized, and throughput can scale well with additional GPUs.
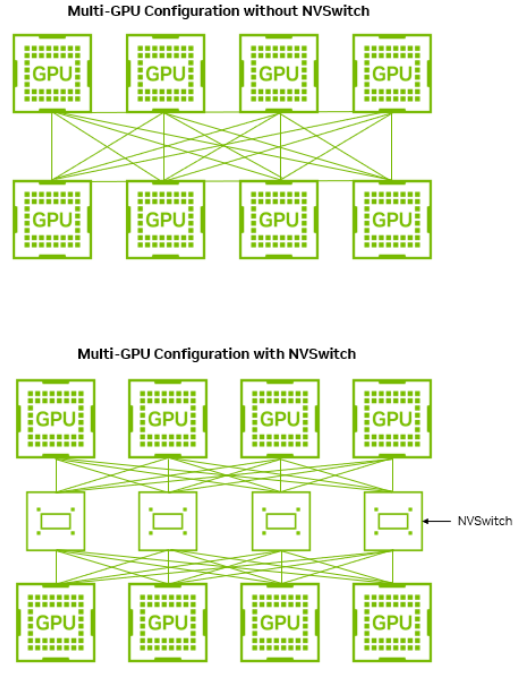
NVLink Switch helps maximize high-throughput performance
Each NVIDIA Hopper architecture GPU incorporates 18 NVLinks with each providing 50 GB/s of bandwidth per direction, providing a total of 900 GB/s of NVLink bandwidth. Each HGX H100 8-GPU or H200 server features four NVLink Switches. During TP model execution across eight GPUs, each GPU communicates to every other GPU using seven, equal-bandwidth connections. This means that communication across any connection happens at 1/7th of NVLink bandwidth, or about 128 GB/s.
PP execution, however, only requires connections to the previous and next stages. This means that communication can happen over two higher-bandwidth connections providing bandwidth of 450 GB/s each. This means that with NVLink and NVLink Switch, effective connection bandwidth between stages is 3.5x higher than would be possible without NVLink Switch. This allows PP to have significantly higher performance than TP in maximum throughput scenarios.
Choosing parallelism is about finding the right balance between compute and capacity for the target scenario. NVLink Switch provides developers with the flexibility to select the optimal parallelism configuration leading to better performance than what is possible with either a single GPU, or across multiple GPUs with tensor parallelism alone.
When considering production deployments – for which LLM service operators may seek to maximize throughput within a fixed latency constraint – the ability to combine both tensor parallelism and pipeline parallelism to achieve desired interactivity while maximizing server throughput for optimal cost is critical. TensorRT-LLM is capable of efficiently combining these techniques. In a future blog post, we will deep dive into picking latency thresholds and GPU configurations to maximize throughput under the desired threshold, and show how NVSwitch improves performance in these online scenarios.
The NVIDIA platform is advancing at the speed of light
The NVIDIA platform provides developers with a full technology stack to optimize generative AI inference performance. NVIDIA Hopper architecture GPUs – available from every major cloud and server maker – connected with the high-bandwidth, NVLink and NVLink Switch AI fabric, and running TensorRT-LLM software provide outstanding performance for the latest LLMs. And, through continuous optimization, we continue to increase performance, lower total cost of ownership, and enable the next wave of AI innovation.