With the rapid expansion of language models over the past 18 months, hundreds of variants are now available. These include large language models (LLMs), small language models (SLMs), and domain-specific models—many of which are freely accessible for commercial use. For LLMs in particular, the process of fine-tuning with custom datasets has also become increasingly affordable and straightforward.
As AI models become less expensive and more accessible, an increasing number of real-world processes and products emerge as potential applications. Consider any process that involves unstructured data—support tickets, medical records, incident reports, screenplays, and much more.
The data involved is often sensitive, and the outcomes are critical to the business. While LLMs make hacking quick demos deceptively easy, establishing the proper processes and infrastructure for developing and deploying LLM-powered applications is not trivial. All the usual enterprise concerns still apply, including how to:
- Access data, deploy, and operate the system safely and securely.
- Set up rapid, productive development processes across the organization.
- Measure and facilitate continuous improvement as the field keeps developing rapidly.
Deploying LLMs in enterprise environments requires a secure and well-structured approach to machine learning (ML) infrastructure, development, and deployment.
This post explains how NVIDIA NIM microservices and the Outerbounds platform together enable efficient, secure management of LLMs and systems built around them. In particular, we focus on integrating LLMs into enterprise environments while following established continuous integration and continuous deployment (CI/CD) best practices.
NVIDIA NIM provides containers to self-host GPU-accelerated microservices for pretrained and customized AI models across clouds, data centers, and workstations. Outerbounds is a leading MLOps and AI platform born out of Netflix, powered by the popular open-source framework Metaflow.
Building LLM-powered enterprise applications with NVIDIA NIM
A substantial share of security and data governance concerns can be readily mitigated by avoiding the need to send data to third-party services. This is a key value proposition of NVIDIA NIM—microservices that offer a large selection of prepackaged and optimized community-created LLMs, deployable in the company’s private environment.
Since the original release of NIM, Outerbounds has been enabling companies to develop LLM-powered enterprise applications, as well as public examples. NIM is now integrated in the Outerbounds platform, enabling you, as the developer, to deploy securely across cloud and on-premises resources. In the course of doing this, Outerbounds has begun to identify emerging patterns and best practices, particularly around infrastructure setup and development workflows.
The term large language model operations (LLMOps) has been coined to encompass many of these practices. However, don’t let the name mislead you. LLMOps centers around the challenges of managing large language model dependencies and operations, while MLOps casts a wider net, covering a broad spectrum of tasks related to overseeing machine learning models across diverse domains and applications.
Many of the topics discussed are established best practices borrowed from software engineering. In fact, it’s advantageous to develop LLM-powered systems using the same principles as any robust software, with particular attention given to the additional challenges posed by the stochastic nature of LLMs and natural language prompts, as well as their unique computational demands.
The following sections highlight learnings in the three main areas that need to be addressed by any serious system:
- Productive development practices
- Collaboration and continuous improvement
- Robust production deployments
These three areas are integral to building LLM-powered enterprise applications with NVIDIA NIM. Productive development practices leverage NIM’s microservices to experiment, fine-tune, and test LLMs securely in private environments. Collaboration and continuous improvement ensure teams can iterate on models, monitor performance, and adapt to changes efficiently. Production deployments with NIM allow enterprises to scale LLM-powered applications securely, whether in the cloud or on-premises, ensuring stability and performance as these systems move from development to real-world use.
This discussion focuses on batch use cases like document understanding, but many elements discussed apply to real-time use cases as well.
Stage 1: Developing systems backed by LLMs
The first stage in building LLM-powered systems focuses on setting up a productive development environment for rapid iteration and experimentation. NVIDIA NIM microservices play a key role by providing optimized LLMs that can be deployed in secure, private environments. This stage involves fine-tuning models, building workflows, and testing with real-world data while ensuring data control and maximizing LLM performance. The goal is to establish a solid development pipeline that supports isolated environments and seamless LLM integration.

Focusing on the development stage first, Outerbounds has found the following elements to be beneficial for developing LLM-powered applications, in particular when dealing with sensitive data:
- Operating within your cloud premises
- Using local compute resources for isolated development environments
- Maximizing LLM throughput to minimize cost
- Supporting domain-specific evaluation
- Customizing models with fine-tuning
Operate within your cloud premises
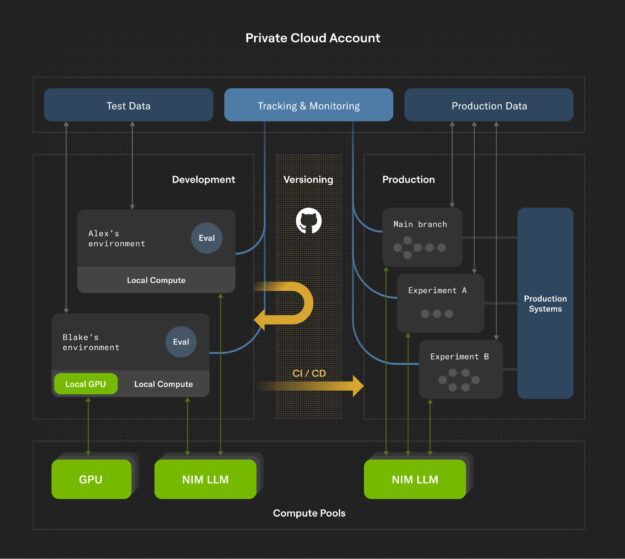
Outerbounds helps you deploy the development environment shown in Figure 1 in your own cloud account(s), so you can develop AI applications, powered by NIM, with your existing data governance rules and boundaries. Furthermore, you can use your existing compute resources for hosting the models without having to pay extra margin for LLM inference.
Flexible, isolated development environments with local compute resources
The two examples in Figure 1 provide personal development environments, where you can operate freely without the risk of interfering with others. This helps to maximize development velocity. NIM exposes an OpenAI-compatible API, which enables hitting the private endpoints using off-the-shelf frameworks, choosing the best tool for each job.In addition to exploring and developing in personal Jupyter Notebooks, you can build end-to-end workflows using open-source Metaflow. Metaflow is a Python library for developing, deploying, and operating various data-intensive applications, in particular those involving data science, ML, and AI. Outerbounds extends Metaflow with an @nim decorator, which makes it straightforward to embed LLM NIM microservices in larger workflows:
MODEL = "meta/llama3-70b-instruct"
PROMPT = "answer with one word HAPPY if the sentiment of the following sentence is positive, otherwise answer with one word SAD"
@nim(models=[MODEL])
class NIMExample(FlowSpec):
...
@step
def prompt(self):
llm = current.nim.models[MODEL]
prompt = {"role": "user", "content": f"{PROMPT}---{doc}"}
chat_completion = llm(messages=[prompt], max_tokens=1)
print('response', chat_completion['choices'][0]['message']['content'])
As a developer, you can execute flows like this locally on your workstation, accessing test data and using any NIM microservices available in the development environment, quickly iterating on prompts and models. For an end-to-end example involving @nim, see 350M Tokens Don’t Lie and the accompanying source code.
Maximizing LLM throughput to minimize cost
In contrast to many third-party APIs, you can hit NIM endpoints in your own environment without rate limiting. Thanks to various NIM optimizations such as dynamic batching, you can increase total throughput by parallelizing prompting. For more details, see Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM Microservices.
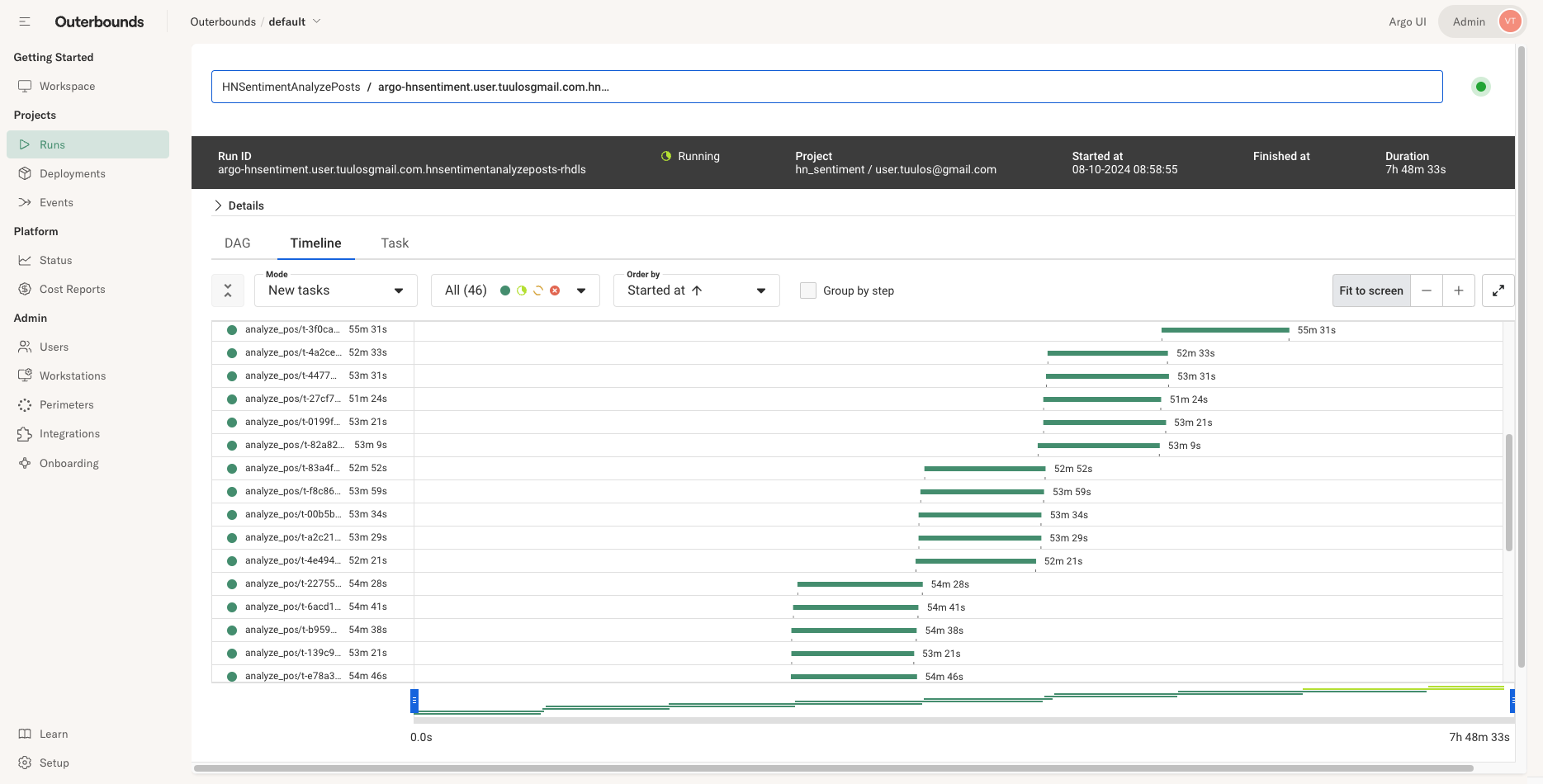
For the 350M Tokens Don’t Lie example, Outerbounds processed 230 million input tokens in about 9 hours with a LLama 3 70B model by hitting the NIM container with five concurrent worker tasks (Figure 2). The model was running on four NVIDIA H100 Tensor Core GPUs.
Since NIM microservices run and autoscale on NVIDIA GPUs hosted in your environment, higher throughput time results in lower cost.
Support domain-specific evaluation
While it may be easy to measure and benchmark raw performance, it’s more difficult to be prescriptive when it comes to evaluating the quality of LLM responses. In general, you need to evaluate responses in the context of your data and application instead of relying on off-the-shelf benchmarks or datasets.
Outerbounds finds it useful to construct case-specific evaluation sets, sometimes supported by a custom UI. This enables you to quickly evaluate results and iterate on prompts. For an example, see Scaling LLM-Powered Document Understanding.
Support model customization through fine-tuning
With the capable LLMs now available, you can often get excellent results with prompt engineering. However, it is beneficial to have the capability to fine-tune the model with custom datasets should a need arise.
While it is possible to fine-tune by resuming training of an LLM, this requires significant compute resources. As an alternative to fine-tuning all of the model’s parameters, it is common to leverage a Parameter-Efficient Fine Tuning (PEFT) technique, which alters only a subset of the model parameters. This can be done with significantly fewer computational resources.
Fortunately, NIM supports PEFT fine-tuning out of the box, so you can use NIM with custom models without having to manually set up an inference stack.
If you’re interested in technical details, take a look at new features that Outerbounds provides for fine-tuning, including an end-to-end example of creating adapters using Metaflow and Hugging Face, and serving them with NIM. The workflow and instructions show how, with a few commands and a few hundred lines of Python code, you can retain complete control over custom workflows for customizing the most potent open-source LLMs.
For instance, consider the development environment depicted in Figure 1. To support fast iterations, a workstation is equipped with a modest local GPU, enabling fast code development. For larger-scale fine-tuning, developers can leverage a larger GPU cluster in the company’s compute pool. In both these cases, fine-tuned models can be quickly evaluated in the development environment prior to deployment to production.
Stage 2: Continuous improvement for LLM systems
Productivity-boosting development environments powered by high-performance LLMs enable rapid development iterations. But speed is not everything. Outerbounds wants to ensure that developers can move fast without breaking things, and strive for coherent, continuous improvement over a long period of time, not just short-term experiments. GitOps, a framework for maintaining version control and continuous improvement using Git is one good way of ensuring this.
Introducing proper version control, tracking, and monitoring to the development environment helps to achieve this (Figure 2).
Versioning code, data, models, and prompts
When using Git or a similar tool for version control, what’s the best way to keep track of prompts, their responses, and models used?
This is where Metaflow built-in artifacts come in handy. Metaflow persists the full workflow state automatically, so by treating prompts and responses as artifacts, everything gets versioned by default and made easily accessible for post-hoc analysis. Notably, artifacts are automatically namespaced and organized, so developer teams can work concurrently and cooperatively.
In addition, you can use Metaflow tags to aid collaboration by annotating particularly successful prompts and runs, so they can be reused easily by others.
Including LLMs in the software supply chain
A crucial but often overlooked part of modern systems powered by LLMs is that the LLM needs to be treated as a core dependency of the system, similar to any other software library. In other words, the LLM—a particular version of the LLM to be exact—becomes a part of the software supply chain. To learn more, see Secure ML with Secure Software Dependencies.
Imagine a system that works well during development and passes the initial evaluation may suddenly break or slowly erode as the backing LLM changes uncontrollably. When using third-party APIs, the vendor must be trusted not to change the model. This is difficult as models evolve and advance at a rapid pace.
Deploying NIM microservices in your environment gives you control of the full model lifecycle. In particular, you can treat the models as a proper dependency of your systems, associating particular prompts and evaluations with an exact model version, down to the hash of the container image producing the results.
Monitoring NIM microservices
Aside from tracking and storing artifacts and metrics, you can instrument critical points throughout a flow, making everything easily observable. One way of doing this is with Metaflow cards, which enable you to attach custom, versioned visualizations to workflows.
When running on Outerbounds, @nim collects metrics about NIM performance automatically, as shown in Figure 4.
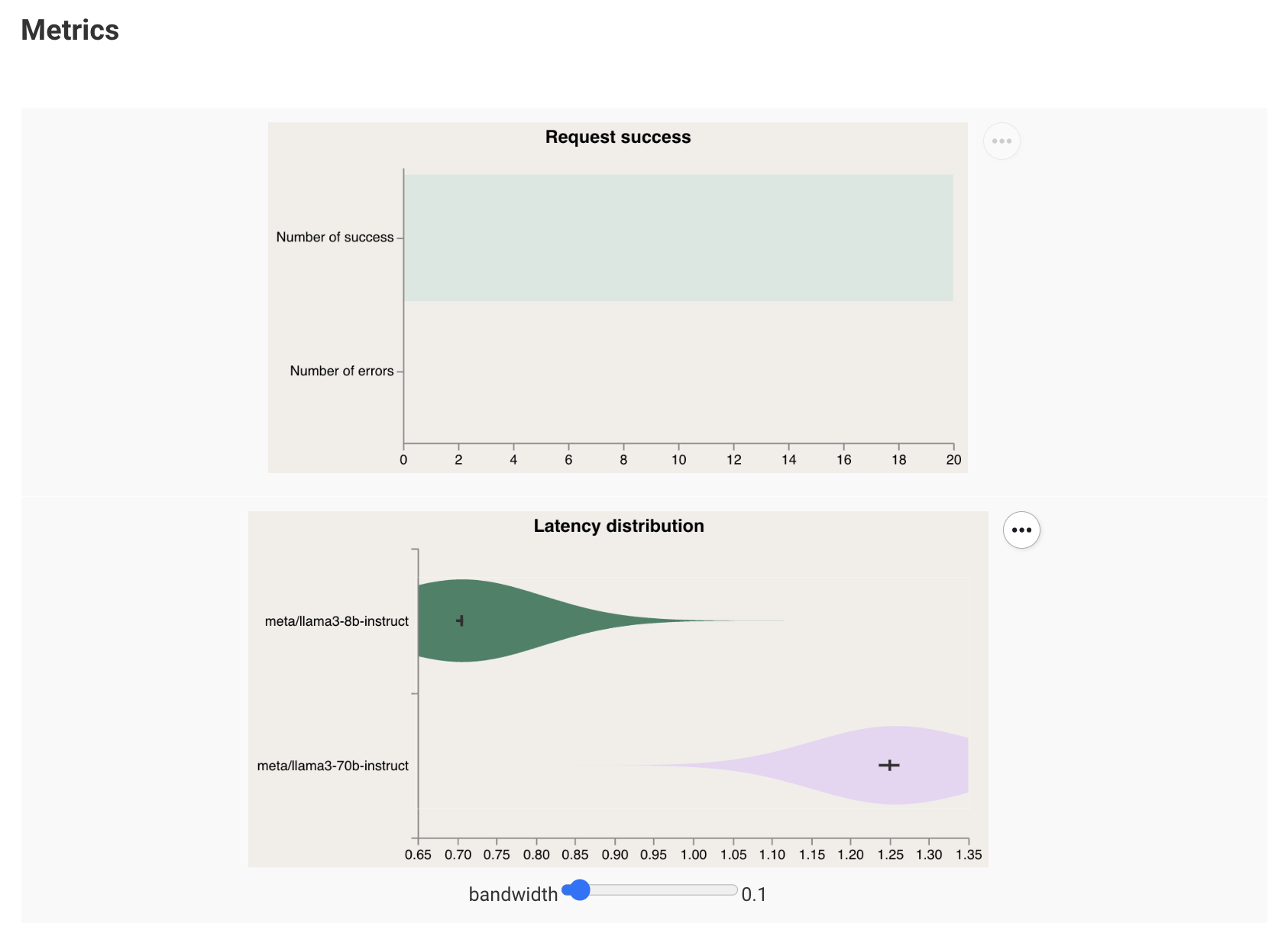
In addition to low-level metrics, you can customize the Metaflow card to show metrics related to the use case. For example, to monitor data drift and alert when the accuracy of responses degrades below a certain threshold.
Stage 3: CI/CD and production roll-outs
In this final stage, the focus shifts to integrating continuous integration and continuous delivery practices to ensure smooth, reliable production roll-outs of LLM-powered systems. By implementing automated pipelines, organizations can continuously improve and update their LLM models while maintaining stability. This stage emphasizes the importance of gradual deployments, monitoring, and version control to manage the complexities of LLM systems in live environments.
Often, moving an LLM to production is perceived as a binary milestone, the crossing of which signals the successful completion of a project. Yet, modern business-critical systems remain incomplete after pushing the deploy button.
Continuous delivery with CI/CD systems
Following DevOps best practices, LLM-powered systems should be deployed through a CI/CD pipeline, such as GitHub Actions. This setup enables continuous deployment of system improvements, which is crucial for systems undergoing rapid iterations, a common scenario with LLMs. Over time, refine prompts, fine-tune models, and upgrade the underlying LLMs, especially as new models are released every few months.
Instead of considering “a deployment” as a one-off action, think of it as a gradual roll-out. Due to the stochastic nature of LLMs, it’s difficult to know whether a new version works better than an old one without exposing it to live data. In other words, deploy it first as an A/B experiment of sorts, or as a shadow deployment running in parallel with production.
This approach leads to multiple versions of LLMs in production concurrently: an existing production version as well as a number of challenger models. Because you control the NIM models, you can more reliably manage roll-outs like this in your own environment. For more details, see How To Organize Continuous Delivery of ML/AI Systems: a 10-Stage Maturity Model.
Isolating business logic and models, unifying compute
To enable stable, highly-available production deployments, they must be securely isolated from development environments. Under no circumstances should development interfere with production (and vice versa).
In the case of LLMs, you may want to experiment with the latest and greatest models, while being more conservative with models in production. Furthermore, when tracking and monitoring production systems, you may need to control who has access to production model responses when sensitive data is involved. You can achieve this by, for example, setting up separate cloud accounts for production and experimentation. You could also use Outerbounds perimeters with role-based access control to set up the desired permission boundaries.
While it’s often a strict requirement to keep logic and data isolated, it’s often beneficial to use shared compute pools across development and production to drive up utilization and hence lower the cost of valuable GPU resources. For example, you can have a unified cluster of GPU (cloud) hardware but deploy a separate set of NIM models in the two environments to guarantee sufficient capacity and isolation for production. To learn more, see The 6 Steps to Cost-Optimized ML/AI/Data Workloads.
Integrating LLM-powered systems into their surroundings
The LLM-powered systems on Outerbounds are not isolated islands. They are connected to upstream data sources, such as data warehouses, and downstream systems consuming their results. This poses additional challenges to deployments, as they have to behave well in the context of other systems too.
You can use Metaflow eventcoming triggering to make your systems react to changes in upstream data sources in real time. When integrating with downstream systems, strong versioning and isolated deployments are a must, to avoid inadvertently breaking compatibility for consumers of your results.
Start building LLM-powered production systems with NVIDIA NIM and Outerbounds
In many ways, systems powered by LLMs should be approached like any other large software system that is subject to stochastic inputs and outputs. The presence of LLMs is similar to a built-in chaos monkey which, when approached correctly, forces building more resilient systems by design.
LLMs are a new kind of a software dependency that is particularly fast-evolving and must be managed as such. NVIDIA NIM delivers LLMs as standard container images, which enables building stable and secure production systems by leveraging battle-hardened best practices, without sacrificing the speed of innovation.
Get started with NVIDIA NIM and Outerbounds.