{kind=link}
The sphere of Natural language processing or NLP has undergone inspiring breakthrough due to the incorporation of state-of-art deep learning techniques. These algorithms have improved the internal flexibility of NLP models exponentially beyond human possibility.
They have excelled in tasks such as text classification, natural language inference, sentiment analysis, and machine translation. By leveraging large amounts of data – these deep learning frameworks are revolutionizing how we process and understand language. They are inspiring high-performance outcomes across countless NLP tasks.
Despite the advances that have been witnessed in the sector of Natural Language Processing (NLP) there are still open issues including risk of adversarial attacks. Usually, such attacks involve injecting small perturbations into the data that are hardly noticeable, but effective enough to deceive an NLP model and skew its results.
The presence of adversarial attacks in natural language processing can pose a challenge, as opposed to continuous data such as images. This is primarily due to the discrete nature of text-based data which renders the effective generation of adversarial examples more complex.
Many mechanisms have been established to defend against the attacks. This article offers an overview of adversarial mechanisms that can be classified under three broad categories: adversarial training-based methods, perturbation control-based methods and certification-based methods.
Overview of Adversarial Attacks in NLP
Understanding of the different types of attacks is imperative to create robust defenses and fostering confidence in NLP models’ reliability.
Types of Attacks
The diagram below describe the different types of attacks.

Adversarial attacks in the field of Natural Language Processing (NLP) have the potential to affect diverse text granularities, spanning from individual characters up to entire sentences. They may also exploit several levels concurrently for more complex attacks.
Black Box vs. White Box Attacks
The classification of adversarial attacks on NLP models can be generally characterized as two types(black-box attacks and white-box attacks) These depend upon the level of access that the attacker has to the model’s parameters. It is imperative to understand these categories to establish defense mechanisms.
White Box Attacks
A white box attack entails an attacker having unrestricted control over all parameters associated with a particular model. Such factors include but are not limited to architecture, gradients and weights – granting extensive knowledge regarding internal operations. From this position of deep insight into said mechanisms, attackers can execute targeted adversarial measures with efficiency and precision.
Adversaries frequently leverage gradient-based methods to detect the most proficient perturbations. By computing the gradients of the loss function with respect to the input, attackers can deduce which modifications to inputs would have a substantial impact on model output.
Owing to the extensive familiarity with the model, white box attacks have a tendency to achieve great success in fooling it.
Black Box Attacks
In the paradigm of black box attacks, access to a given model’s parameters and architecture remains restricted for attackers. However, their communication with the model is restricted to input, to which the model responds with outputs.
The very nature of such an attacker is restricted, which makes black box attacks more complex. The observed queries are the only means by which they are forced to deduce the model’s inherent behavior.
Often, attackers engage in the process of training a surrogate model that emulates the patterns of operation exhibited by its intended target. This surrogate model is subsequently employed to formulate instances of adversarial nature.
Challenges in Generating NLP Adversarial Examples
The generation of effective adversarial examples in natural language processing (NLP) is a multifaceted undertaking that presents inherent challenges. These challenges arise from the complexity of linguistics, NLP model behavior, and constraints associated with attack methodologies. We will summarize these challenges in the following table:
| Challenge | Description |
|---|---|
| Semantic Integrity | Ensuring adversarial examples are semantically similar to the original text. |
| Linguistic Diversity | Maintaining naturalness and diversity in the text to evade detection. |
| Model Robustness | Overcoming the defenses of advanced NLP models. |
| Evaluation Metrics | Lack of effective metrics to measure adversarial success. |
| Attack Transferability | Achieving transferability of attacks across different models. |
| Computational Resources | High computational demands for generating quality adversarial examples. |
| Human Intuition and Creativity | Utilizing human creativity to generate realistic adversarial examples. |
These challenges underscore the need for continued research and development efforts to advance the domain of adversarial attacks in natural language processing. They also highlight the importance to improve NLP systems’ resilience against such attacks.
Adversarial Training-Based Defense Methods
The primary objective of adversarial training-based defense is to enhance the model’s resilience. It’s achieved by subjecting it to adversarial examples during its training phase. Additionally, it involves integrating an adversarial loss into the overall training objective.
Data Augmentation-Based Approaches
Approaches based on data augmentation entail creating adversarial examples and incorporating them into the training dataset. This strategy facilitates the development of a model’s ability to manage perturbed inputs, enabling it to withstand attacks from adversaries with resilience.
For example, some methods may involve introducing noise into word embeddings or implementing synonym substitution as a means for generating adversarial examples. There are different approaches to performing data augmentation-based adversarial training. These include word level data augmentation, concatenation based data augmentation and generation based data augmentation.
Word-Level Data Augmentation
At the word-level, text data augmentation can be performed by applying some perturbations directly to the words of the input text. This can be achieved by substitution, addition, omission, or repositioning of words in a sentence or document. Through these perturbations, the model is trained to detect and address adversarial changes that occurs.
For exemple, the phrase “The movie was fantastic” may be transformed into “The film was great.” Using these augmented datasets for training enables the model to generalize better and reduces its vulnerability against input perturbations.
Concatenation-Based and Generation-Based Data Augmentation
In concatenation-based approach, new sentences or phrases are added to the original text. This method can inject adversarial examples by concatenating other information that might change the model’s predictions. For example, in an image classification scenario, an adversarial example might be created by adding a misleading sentence to the input text.
The generation-based data augmentation generates new adversarial examples using generative models. Using Generative Adversarial Networks (GANs), it’s possible to create adversarial texts that are syntactically and semantically correct. These generated examples are then incorporated into the training set to enhance the diversity of adversarial scenarios.
Regularization Techniques
Regularization techniques add adversarial loss to the training objective. This encourages the model to produce the same output for clean and adversarial pertubed inputs. By minimizing the difference in predictions on clean and adversarial examples, these methods make the model more robust to small perturbations.
In machine translation, regularization can be used to ensure that the translation is the same even if the input is slightly perturbed. For example, translating “She is going to the market” should give the same result if the input is changed to “She’s going to the market”. This consistency makes the model more robust and reliable in real world applications.
GAN-Based Approaches
GANs use the power of Generative Adversarial Networks to improve robustness. In these methods a generator network creates adversarial examples and a discriminator network tries to distinguish between real and adversarial inputs. This adversarial training helps the model to learn to handle a wide range of possible perturbations. GANs have shown promise to improve performance on clean and adversarial inputs.
In a text classification task a GAN can be used to generate adversarial examples to challenge the classifier. For example generating sentences that are semantically similar but syntactically different, like changing “The weather is nice” to “Nice is the weather” can help the classifier to learn to recognize and classify these variations.
Virtual Adversarial Training and Human-In-The-Loop
Specialized techniques for adversarial training include Virtual Adversarial Training (VAT) and Human-In-The-Loop (HITL). VAT works by generating perturbations that maximize the model’s prediction change in a small vicinity around each input. This improves local smoothness and robustness of the model.
On the contrary, HITL methods include human input during adversarial training. By requiring input from humans to create or validate challenging examples, these approaches generate more realistic and challenging inputs. This enhances a model’s resilience against attacks.
All of these defense methods look very effective. They also present a set of approaches to enhance the resilience of NLP models from adversarial attacks. During model training, these approaches ensure models are trained with different types of adversarial examples hence making the NLP systems more robust.
Perturbation Control-Based Defense Methods
In NLP, defense techniques based on perturbation control aim to detect and alleviate negative impacts caused by adversarial perturbations. These strategies can be classified into two methods: perturbation identification and correction, and perturbation direction control.
The main objective of perturbation identification and correction techniques is to detect and address adversarial perturbations in the input text. They usually employ a few techniques to detect suspicious or adversarial inputs. For example, to detect out-of-distribution words or phrases, the model can use language models or rely on statistical techniques to detect unusual patterns in the text. After detection, these perturbations can be fixed or removed to bring the text back to its original meaning as intended.
On the other hand, perturbation direction control methods lean towards controlling the direction of possible perturbations to reduce their effect on the model’s outcome. Such techniques are usually applied by changing either the structure of the model or the training process itself to enhance the model’s robustness against specific types of perturbations.
Enhancing the Robustness of Customer Service Chatbots Using Perturbation Control-Based Defense Methods
Organizations are adopting customer service chatbots to manage customer inquiries and offer assistance. Nevertheless, these chatbots can be susceptible to adversarial attacks. Slight modifications in the input text may result in inaccurate or unreliable responses. To reinforce the resilience of such chatbots, defense mechanisms based on perturbation control can be used.
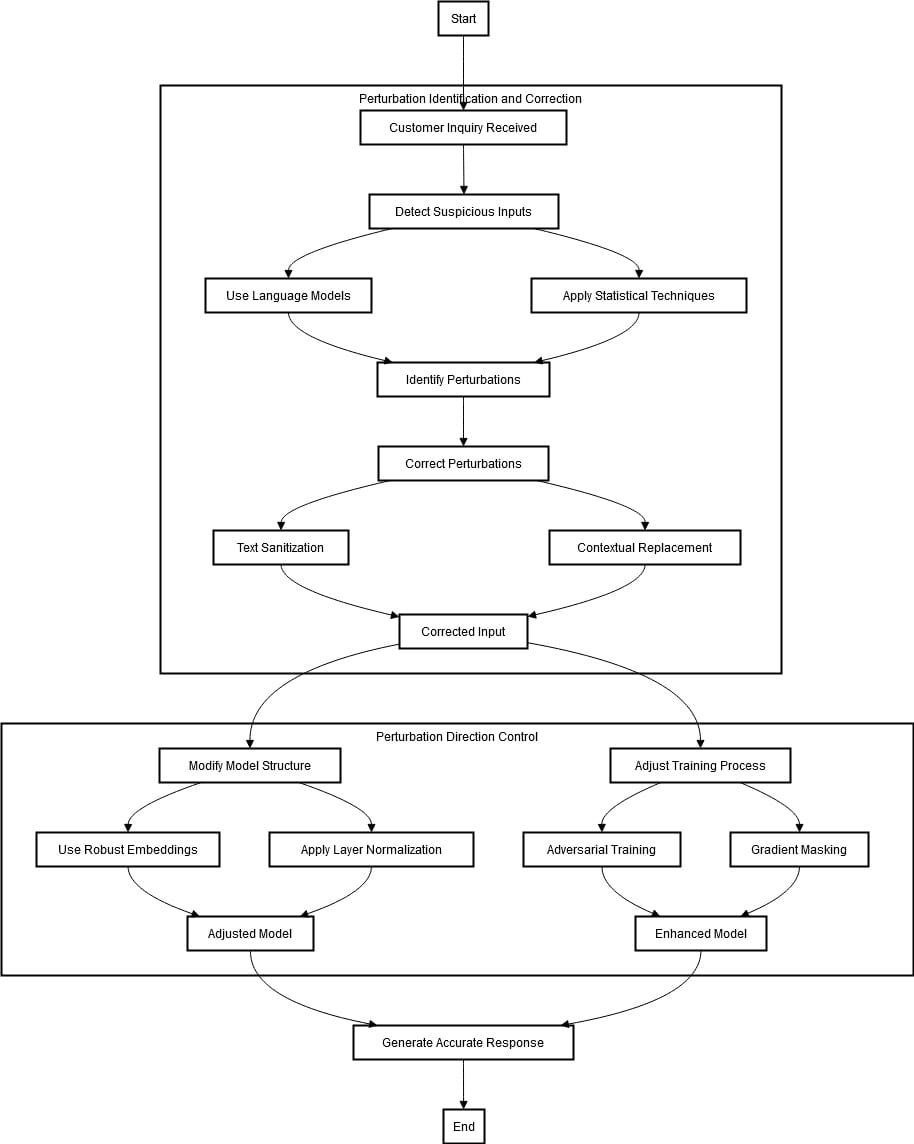
The process starts by receiving a request from a customer. The first step is to identify and correct any perturbations in the input text that may be adversarial. This is achieved through language models and statistical techniques that recognize unusual patterns or out-of-distribution words indicative of such attacks. Once detected, they can be corrected through text sanitization (e.g., correcting spelling errors), or contextual replacement (i.e., replacing inappropriate words with more relevant ones).
The second stage focuses on perturbation direction control. This includes enhancing the chatbot’s resistance against adversarial attacks. This can be achieved by adjusting the training process and modifying its model structure. To make it less vulnerable to slight modifications in the input text, robust embeddings, and layer normalization techniques are incorporated into the system.
The training mechanism is adjusted by integrating adversarial training and gradient masking. This process entails training the model on original and adversarial inputs, ensuring its capacity to proficiently manage perturbations.
Certification-Based Defense Methods in NLP
Certification-based defense methods offer a formal level of assurance of resistance against adversarial attacks in NLP models. These techniques ensure that the model performances remain consistent in a given neighborhood of the input space and can be considered as a more rigorous solution to the model robustness problem.
In contrast to adversarial training or perturbation control methods, certification-based methods allow proving mathematically that a particular model is robust against certain types of adversarial perturbations.
In the context of NLP, certification methods usually entails the specification of a set of allowable perturbation (for example, replacement of words, characters, etc.) of the original input and then ensuring the model’s output remains consistent for all inputs within this defined set.
There are various methods to compute provable upper bounds on a model’s output variations under input perturbations.
Linear Relaxation Techniques
Linear relaxation techniques involve approximating the non-linear operations that exist in a neural network by linear bounds. These techniques transform the exact non-linear constraints into linear ones.
Solving these linearized versions, we can get the upper and lower bounds of the output variations. Linear relaxation techniques provide a balance between computational efficiency and the tightness of the bounds, offering a practical way to verify the robustness of complex models.
Understanding Interval Bound Propagation
Interval bound propagation is a way to make the neural network models less sensitive to perturbation and to compute the interval of the network outputs. This method aids in ensuring that the model’s outputs stay bounded even when the inputs may be slightly changed.
The process can be defined as follows:
- Input Intervals: The first step in this process involves identifying ranges for the inputs of the model. An interval is a collection of values which may be taken by the input. For example, if the input is a single number, an interval might be [3. 5, 4. 5]. This means that the input is within the range of the two numbers: 3. 5 and 4. 5.
- Propagation through Layers: The input intervals are then transformed through the layer’s operations as they progress through the layers of the neural network. The output of each layer is also an interval. If the input interval is [3. 5, 4. 5] and the layer performed a multiplication by 2 on each of the inputs, the current interval would be [7. 0, 9. 0].
- Interval Representation: The output is an interval that contains all values that the layer’s output can take given the input interval. This means if there are any pertubations within the input interval, the output interval will still encompass all the possible ranges.
- Systematic Tracking: The intervals are tracked systematically through each layer of the network. This involves updates of intervals at each step to accurately reflect possible output values in the next step after transformation. Example: If the second layer adds 1 to the output, the interval [7.0, 9.0] becomes [8.0, 10.0].
- Guaranteed Range: By the time the input intervals have propagated through all the layers of the network, the final output interval provides a guaranteed range of values. This range indicates all possible outputs the model can produce for any input within the initial interval.
The above process can be visualized in the diagram below.
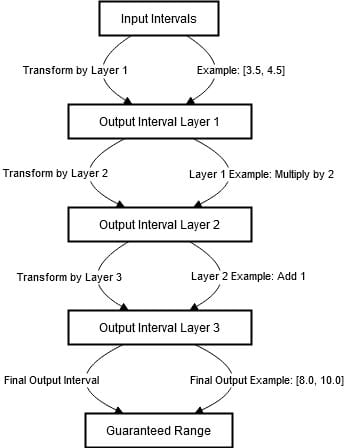
The above diagram highlights the steps taken to ensure that the outputs of the neural network are bounded despite of the input variations. It starts with the specification of the first input intervals.
When passing through layers of the network, inputs undergo more modifications such as multiplication and addition which modify the intervals.
For example, multiplying by 2 shifts the interval to [7. 0,9. 0], while adding 1 changes the interval to [8. 0,10. 0]. In each layer, the output provided as an interval encompasses all the possible values given the range of inputs.
Through this systematic tracking through the network, it’s possible to guarantee the output interval. This makes the model resistant to small inputs.
Randomized Smoothing
On the other hand, randomized smoothing is another technique that involves adding random noise to inputs. It also includes statistical methods to guarantee robustness against known attacks and potential ones. The diagram below describe the process of randomized smoothing.
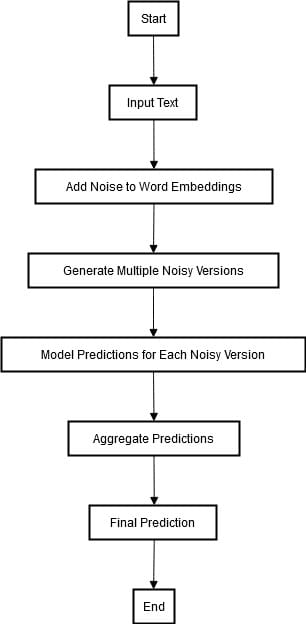
In randomized smoothing, random noise is added to the word embeddings of a particular input text to get multiple perturbed versions of the text. Afterward, we integrate each noisy version into the model and produce an output for each of them.
These predictions are then combined, usually by a majority voting or probability averaging, to produce the final consistent prediction. This approach ensures that the model’s outputs remain stable and accurate, even when the input text is subjected to small adversarial perturbations. By doing so, it strengthens the robustness of the model against adversarial attacks.
Practical Use Case: Robustness in Automated Legal Document Review
A legal tech company decides to build an NLP system for lawyers that would let them automatically review and summarize legal documents. The proper functioning of this system must be guaranteed because any error may lead to legal and financial penalties.
Use Case Implementation
- Problem: The system must be robust against adversarial inputs, including sentences or phrases that are intended to fool the model into providing faulty interpretations or summaries.
- Solution: Using certification-based defense mechanisms to ensure that the model remains reliable and secure.
Interval Bound Propagation
Interval bound propagation is incorporated into the NLP model of the legal tech company. When analysing a legal document, the model performs mathematical calculations to compute the intervals for every portion of the text. Even if some words or phrases have been slightly pertubed(for example, because of typo mistakes, or slight shifts in meaning), the calculated interval will still fall into a trustworthy range.
Exemple: If the original phrase is “contract breach,” a slight perturbation might change it to “contrct breach.” The interval bounds would make sure that the model knows that this phrase is still related to “contract breach.”
Linear Relaxation
The company approximate the nonlinear components of the NLP model using the linear relaxation technique. For example, the complex interactions between legal terms are simplified into linear segments, which are easier to verify for robustness.
Exemple: Terms such as ‘indemnity’ and ‘liability’ might interact in complex ways within a document. Linear relaxation approximates these interactions into simpler linear segments. This helps ensure that slight variations or typos of these terms such as using ‘indemnity’ to ‘indemnityy’ or ‘liability’ to ‘liabilitty’ don’t mislead the model.
Randomized Smoothing
- Application: The company uses randomized smoothing by adding some random noise to the input legal documents during data preprocessing. For example, small variations in the wording or phrasing are incorporated in order to smooth out the decision boundaries of the model.
- Statistical Analysis: Statistical analysis is performed on the model’s output to confirm that while noise has been incorporated, the fundamental legal interpretations/summaries are not affected.
Exemple: During preprocessing, phrases like “agreement” might be randomly varied to “contract” or “understanding.” Randomized smoothing ensures these variations do not affect the fundamental legal interpretation.
This approach facilitates the mitigation of unpredictable or substantial changes in model output resulting from small input variations (e.g., due to noise or minor adversarial alterations). As a result, it enhances the model’s robustness.
In contexts where reliability is of utmost importance, such as in self-driving automobiles or clinical diagnostic systems, interval-bound propagation offers a systematic approach to guarantee that the outcomes generated by a model are secure and reliable under a range of input conditions.
Conclusion
Deep learning approaches have been incorporated into NLP and have offered excellent performance with various tasks. With the increase in the complexity of these models, they become vulnerable to adversarial attacks that can manipulate them. Mitigating these vulnerabilities is crucial for improving the stability and reliability of the NLP systems.
This article provided several defense approaches for adversarial attacks such as adversarial training-based approach, perturbation control-based approach, and certification-based approach. All these approaches help to improve the robustness of the NLP models against adversarial perturbations.
Reference
A Survey of Adversarial Defences and Robustness in NLP