{kind=link}
In the rapidly evolving field of medicine, the integration of cutting-edge technologies is crucial for enhancing patient care and advancing research. One such innovation is retrieval-augmented generation (RAG), which is transforming how medical information is processed and used.
RAG combines the capabilities of large language models (LLMs) with external knowledge retrieval, addressing critical limitations such as outdated information and the generation of inaccurate data, known as hallucinations. By retrieving up-to-date and relevant information from structured databases, scientific literature, and patient records, RAG provides a more accurate and contextually aware foundation for medical applications. This hybrid approach improves the accuracy and reliability of generated outputs and enhances interpretability, making it a valuable tool in areas like drug discovery and clinical trial screening.
As we continue to explore the potential of RAG in medicine, it is essential to evaluate its performance rigorously, considering both the retrieval and generation components to ensure the highest standards of accuracy and relevance in medical applications. Medical RAG systems have unique demands and requirements, highlighting the need for comprehensive evaluation frameworks that can robustly address them.
In this post, I show you how to address medical evaluation challenges using LangChain NVIDIA AI endpoints and Ragas. You use the MACCROBAT dataset, a dataset of detailed patient medical reports taken from PubMed Central, enriched with meticulously annotated information.
Challenges of Medical RAG
One primary challenge is scalability. As the volume of medical data grows at a CAGR of >35%, RAG systems must efficiently process and retrieve relevant information without compromising speed or accuracy. This is crucial in real-time applications where timely access to information can directly impact patient care.
The specific language and knowledge required for medical applications can differ vastly from other domains, such as legal or financial sectors, limiting the system’s versatility and requiring domain-specific tuning.
Another critical challenge is the lack of medical RAG benchmarks and the inadequacy of general evaluation metrics for this domain. The lack of benchmarks requires the generation of synthetic test and ground truth data based on medical texts and health records.
Traditional metrics like BLEU or ROUGE, which focus on text similarity, do not adequately capture the nuanced performance of RAG systems. These metrics often fail to reflect the factual accuracy and contextual relevance of the generated content, which are crucial in medical applications.
Finally, evaluating RAG systems also involves assessing both the retrieval and generation components independently and as a whole. The retrieval component must be evaluated for its ability to fetch relevant and current information from vast and dynamic knowledge bases. This includes measuring precision, recall, and relevance, while also considering the temporal aspects of information.
The generation component, powered by large language models, must be evaluated for the faithfulness and accuracy of the content it produces, ensuring that it aligns with the retrieved data and the original query.
Overall, these challenges highlight the need for comprehensive evaluation frameworks that can address the unique demands of medical RAG systems, ensuring they provide accurate, reliable, and contextually appropriate information.
What is Ragas?
Ragas (retrieval-augmented generation assessment) is a popular, open-source, automated evaluation framework designed to evaluate RAG pipelines.
The Ragas framework provides tools and metrics to assess the performance of these pipelines, focusing on aspects such as context relevancy, context recall, faithfulness, and answer relevancy. It employs LLM-as-a-judge for reference-free evaluations, which minimizes the need for human-annotated data and provides human-like feedback. This makes the evaluation process more efficient and cost-effective.
Strategies for evaluating RAG
A typical strategy for robust evaluation of RAG follows this process:
- Generate a set of synthetically generated triplets (question-answer-context) based on the documents in the vector store.
- Run evaluation precision/recall metrics for each sample question by running it through the RAG and comparing the response and context to ground truth.
- Filter out low-quality synthetic samples.
- Run the sample queries on the actual RAG and evaluate using the metrics using synthetic context and response as ground truth.

To make the best use of this tutorial, you need a basic knowledge of LLM inference pipelines.
Set up
To get started, create a free account with the NVIDIA API Catalog and follow these steps:
- Select any model.
- Choose Python, Get API Key.
- Save the generated key as
NVIDIA_API_KEY.
From there, you should have access to the endpoints.
Now, install LangChain, NVIDIA AI endpoints, and Ragas:
pip install langchain
pip install langchain_nvidia_ai_endpoints
pip install ragas
Download the medical dataset
Next, download the Kaggle MACCROBAT dataset. You can either download the dataset directly from Kaggle (requires the Kaggle API token) or use the /MACCROBAT_biomedical_ner version from Hugging Face.
For this post, you use the full text from the medical reports and ignore the NER annotations:
from langchain_community.document_loaders import HuggingFaceDatasetLoader
from datasets import load_dataset
dataset_name = "singh-aditya/MACCROBAT_biomedical_ner"
page_content_column = "full_text"
loader = HuggingFaceDatasetLoader(dataset_name, page_content_column)
dataset = loader.load()
Generate synthetic data
One of the key challenges in RAG evaluation is the generation of synthetic data. This is required for robust evaluation, as you want to test your RAG system on questions relevant to the data in the vector database.
A key benefit of this approach is that it enables wide testing while not requiring costly human-annotated data. A set of LLMs (generator, critic, embedding) are used to generate representative synthetic data based on relevant data. Ragas uses OpenAI by default so you override this to use NVIDIA AI endpoints instead.
from ragas.testset.generator import TestsetGenerator
from ragas.testset.evolutions import simple
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
critic_llm = ChatNVIDIA(model="meta/llama3.1-8b-instruct")
generator_llm = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1")
embeddings = NVIDIAEmbeddings(model="nv-embedqa-e5-v5", truncate="END")
generator = TestsetGenerator.from_langchain(
generator_llm,
critic_llm,
embeddings,
chunk_size=512
)
# generate testset
testset = generator.generate_with_langchain_docs(dataset, test_size=10, is_async=False, raise_exceptions=False, distributions={simple: 1.0})
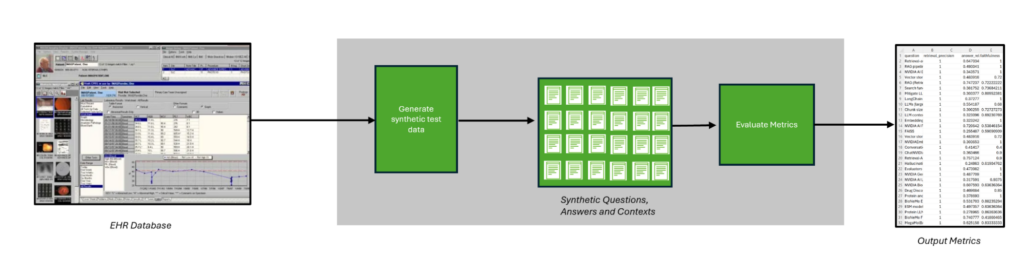
Deploy the code on a vector store based on medical reports from the MACCROBAT dataset. This generates a list of sample questions based on the actual documents in the vector store:
[“What are typical BP measurements in the case of congestive heart failure?”,
“What can scans reveal in patients with severe acute pain in the periumbilical region?”
“Is surgical intervention required for the treatment of a metachronous solitary liver metastasis?”
“What are the most effective procedures for detecting gastric cancer?”]
In addition, each of the questions is associated with a retrieved context and generated ground truth answer, which you can later use to independently evaluate and grade the retrieval and generation components of the medical RAG.
Evaluate the input data
You can now use the synthetic data as input data for evaluation. Populate the input data with the generated questions (question) and responses (ground_truth), as well as the actual retrieved contexts from your medical RAG system (contexts) and their respective responses (answer).
In this code example, you evaluate generation-specific metrics (answer_relevancy, faithfulness):
# answer relevance and faithfulness metrics ignore ground truth, so just fill it with empty values
ground_truth = ['']*len(queries)
answers = []
contexts = []
# Run queries in search endpoint and collect context and results
for query in queries:
json_data = query_rag(query)
response =json_data['results'][0]['answer']
answers.append(response)
seq_str = []
seq_str.append(json_data['results'][0]['retrieved _document_context'])
contexts.append(seq_str)
# Store all data in HF dataset for RAGAS
data = {
"question": queries,
"answer": answers,
"contexts": contexts,
"ground_truth": ground_truth
}
dataset= DatasetDict()
dataset['eval']=Dataset.from_dict(data)
# Override OpenAI LLM and embedding with NVIDIA AI endpoints
nvidia_llm = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
nvidia_embeddings = NVIDIAEmbeddings(model="nvidia/nv-embedqa-e5-v5", truncate="END")
result = evaluate(
dataset["eval"],
metrics=[answer_relevancy,
faithfulness
],
llm=nvidia_llm,
embeddings=nvidia_embeddings,
raise_exceptions=False,
is_async=False,
)
Apply to semantic search
You can further modify the system to evaluate semantic search based on keywords, as opposed to question/answer pairs. In this case, you extract the keyphrases from Ragas and ignore the generated testset of question/answer data. This is often useful in medical systems where a full RAG pipeline is not yet deployed.
testset = generator.generate_with_langchain_docs([doc], test_size=10, is_async=False, raise_exceptions=False, distributions={simple: 1.0})
queries = []
for node in generator.docstore.nodes:
queries += node.keyphrases
return queries
This now generates queries, as opposed to questions, which you can feed into any medical semantic search system for evaluation:
[“lesion”, “intraperitoneal fluid”, “RF treatment”, “palpitations”, “thoracoscopic lung biopsy”, “preoperative chemoradiotherapy”, “haemoglobin level”, “needle biopsy specimen”, “hypotension”, “tachycardia”, “abdominal radiograph”, “pneumatic dilatation balloon”, “computed tomographic (CT) scan”, “tumor cells“, “radiologic examinations“, “S-100 protein“, “ultrastructural analysis”, “Birbeck granules”, “diastolic congestive heart failure (CHF)”, “Brachial blood pressure”, “ventricular endomyocardial biopsy”, “myocarditis”, “infiltrative cardiomyopathies”, “stenosis”, “diastolic dysfunction”, “autoimmune hepatitis”]
Customizing for semantic search
As mentioned earlier, default evaluation metrics are not always sufficient for medical systems, and often must be customized to support domain-specific challenges.
To this end, you can create custom metrics in Ragas. This requires creating a custom prompt. In this example, you create a custom prompt to measure retrieval precision for a semantic search query:
RETRIEVAL_PRECISION = Prompt(
name="retrieval_precision",
instruction="""if a user put this query into a search engine, is this result relevant enough that it could be in the first page of results? Answers should STRICTLY be either '1' or '0'. Answer '0' if the provided summary does not contain enough information to answer the question and answer '1' if the provided summary can answer the question.""",
input_keys=["question", "context"],
output_key="answer",
output_type="json",
)
Next, build a new class inheriting from MetricWithLLM and override the _ascore function to compute a score based on the prompt response:
@dataclass
class RetrievalPrecision(MetricWithLLM):
name: str = "retrieval_precision" # type: ignore
evaluation_mode: EvaluationMode = EvaluationMode.qc # type: ignore
context_relevancy_prompt: Prompt = field(default_factory=lambda: RETRIEVAL_PRECISION)
async def _ascore(self, row: t.Dict, callbacks: Callbacks, is_async: bool) -> float:
score=response[0] # first token is the result [0,1]
if score.isnumeric():
return int(score)
else:
return 0
retrieval_precision = RetrievalPrecision()
Now your new custom metric is defined as retrieval_precision and you can use it in the standard Ragas evaluation pipeline:
nvidia_llm = ChatNVIDIA(model="meta/llama-3.1-8b-instruct")
nvidia_embeddings = NVIDIAEmbeddings(model="nvidia/nv-embedqa-e5-v5", truncate="END")
score = evaluate(dataset["eval"], metrics=[retrieval_precision], llm=nvidia_llm, embeddings=nvidia_embeddings, raise_exceptions=False, is_async=False)
Refining with structured output
RAG and LLM evaluation frameworks employ LLM-as-a-judge techniques, often requiring long and complicated prompts. As you saw in the earlier example of a custom metric prompt, this also requires parsing and post-processing of the LLM response.
You can refine this process, making it more robust, by using the structured output feature of LangChain NVIDIA AI endpoints. Modifying the earlier prompt yields a simplified pipeline:
import enum
class Choices(enum.Enum):
Y = "Y"
N = "N"
structured_llm = nvidia_llm.with_structured_output(Choices)
structured_llm.invoke("if a user put this query into a search engine, is this result relevant enough that it could be in the first page of results? Answer 'N' if the provided summary does not contain enough information to answer the question and answer 'Y' if the provided summary can answer the question.")
Conclusion
RAG has emerged as a powerful approach, combining the strengths of LLMs and dense vector representations. By using dense vector representations, RAG models can scale efficiently, making them well-suited for large-scale enterprise applications, such as multilingual customer service chatbots and code generation agents.
As LLMs continue to evolve, it is clear that RAG will play an increasingly important role in driving innovation and delivering high-quality, intelligent systems in medicine.
When evaluating a medical RAG system, it’s crucial to consider several key factors:
- The system should provide accurate, relevant, and up-to-date information while remaining faithful to the retrieved context.
- It must demonstrate robustness in handling specialized medical terminology and concepts, as well as noisy or imperfect inputs.
- Proper evaluation involves using appropriate metrics for both retrieval and generation components, benchmarking against specialized medical datasets, and considering cost-effectiveness.
- Incorporating feedback from healthcare professionals and conducting continuous evaluations are essential to ensure the system’s practical utility and relevance in clinical settings.
The pipeline described in this post addresses all these points and can be further embellished to include additional metrics and features.
For more information about a reference evaluation tool using Ragas, see the evaluation example on the /NVIDIA/GenerativeAIExamples GitHub repo.