Google has solidified its artificial intelligence strategy, moving its powerful Gemini 2.5 Pro and 2.5 Flash models into general availability for production use while simultaneously expanding its portfolio with a new, cost-effective model named Gemini 2.5 Flash-Lite. The company established a clear three-tiered product family, a significant move designed to give developers a predictable and tailored set of options that balance performance, speed, and cost.
The strategic overhaul brings clarity to what had been a fast-moving and sometimes confusing series of preview releases, signaling a new phase of stability for developers building on Google’s platform. In a post on The Keyword, Google’s official blog, Senior Director Tulsee Doshi framed the strategy, explaining the goal was to create a “family of hybrid reasoning models” that deliver top-tier performance while remaining at the “Pareto Frontier of cost and speed.”
This maturation is further underscored by a major simplification in the pricing for Gemini 2.5 Flash, which abandons a complex preview structure for a single, unified rate.
A Model for Every Mission: Pro, Flash, and Flash-Lite
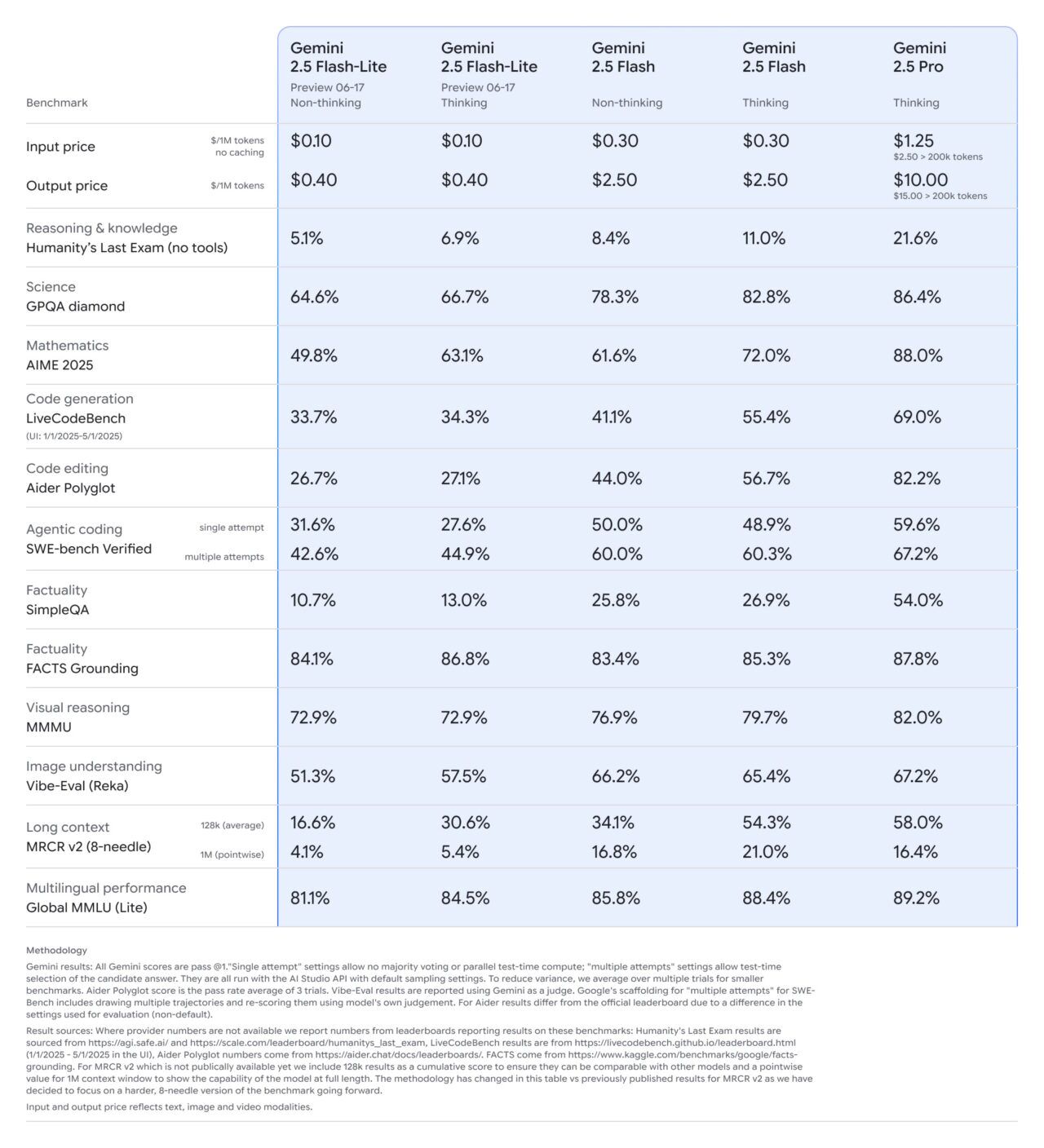
The newly defined hierarchy creates distinct roles for each model, a strategy detailed in Google’s official documentation for developers. At the top, Gemini 2.5 Pro is positioned for ‘maximum response accuracy and state-of-the-art performance,’ making it the engine for the most complex coding, analysis, and agentic tasks. Internal benchmarks show it leading in difficult domains like mathematics and code editing.
Occupying the middle tier is Gemini 2.5 Flash, engineered for ‘low latency, high volume tasks that require thinking.’ It serves as a balanced all-rounder, offering performance that often approaches Pro but at a significantly lower cost. The hierarchy is not always strictly linear, however; in a notable nuance from Google’s own testing, the Flash model with thinking enabled actually outperformed the more powerful Pro model on a specific long-context retrieval benchmark, suggesting specialized optimizations within the architecture.
The newest member, Gemini 2.5 Flash-Lite, is the speed and scale specialist. Now available in preview, it is described as the ‘most cost-efficient model supporting high throughput’ for real-time applications like data classification and summarization at scale.

Pricing, Simplified: A Clearer Path for Developers
A critical component of this strategic clarification is the updated pricing for Gemini 2.5 Flash. During its preview phase, which began in April, the model featured a confusing dual-pricing system based on whether its reasoning feature was active. Google has now eliminated that complexity, setting a single rate of $0.30 per million input tokens and $2.50 per million output tokens.
The company explained the adjustment was a specific reflection of the model’s ‘exceptional value,’ adding that it still offers the ‘best cost-per-intelligence available.’ This change, a direct response to developer feedback, simplifies cost forecasting for businesses. The pricing structure is further clarified by the Gemini API’s ‘free tier’, which offers developers a way to experiment with lower rate limits before committing to the higher-volume paid tier.
The ‘Thinking’ Advantage: Controllable AI Reasoning
Central to the entire 2.5 family is the concept of ‘hybrid reasoning,’ a controllable feature that allows the models to perform deeper, multi-step logical verification before responding. This is more than a simple toggle; developers can set a ‘thinking budget’ to control the computational resources a model uses for reasoning on a per-query basis.
This granular control allows for a precise trade-off between response quality, latency, and cost. The feature, first introduced with the 2.5 Flash preview extended to Gemini 2.5 Pro in May, is a core part of the family’s architecture. Its impact is tangible: enabling ‘thinking’ on Gemini 2.5 Flash-Lite, for example, boosts its score on a key mathematics benchmark from 49.8% to 63.1%, giving developers a lever to enhance accuracy when needed.
From Sprints to Stability: A Maturing AI Strategy
This structured rollout marks a significant shift from the atmosphere surrounding the initial release of the Gemini 2.5 series. In late March, Google pushed its experimental 2.5 Pro model to all free users just days after its exclusive launch to paying subscribers. The company’s social media account declared at the time, “The team is sprinting, TPUs are running hot, and we want to get our most intelligent model into more people’s hands asap.”
That rapid deployment, however, was met with criticism from AI governance experts when the accompanying safety report arrived weeks later with what some considered meager details. Kevin Bankston of the Center for Democracy and Technology described it at the time as part of a “troubling story of a race to the bottom on AI safety and transparency as companies rush their models to market.”
Today’s announcement of ‘General Availability’ signals a strategic maturation. As noted in Vertex AI release notes, this status implies the models are stable, supported for production use, and come with service-level agreements. This shift from experimental sprints to a stable, tiered, and predictably priced product family shows Google is building a more durable foundation for its broad AI ambitions, which were on full display at its recent I/O conference.