LMArena at the University of California, Berkeley is making it easier to see which large language models excel at specific tasks, thanks to help from NVIDIA and Nebius. Its rankings, powered by the Prompt-to-Leaderboard (P2L) model, collect votes from humans on which AI performs best in areas such as math, coding, or creative writing.
“We capture user preferences across tasks and apply Bradley-Terry coefficients to identify which model performs best in each domain,” said Wei-Lin Chiang, co-founder of LMArena and a doctoral student at Berkeley. LMArena (formerly LMSys) has been developing P2L for the past two years.
LMArena is working with NVIDIA DGX Cloud and Nebius AI Cloud to deploy P2L at scale. This collaboration—and LMArena’s use of NVIDIA GB200 NVL72—has enabled the development of scalable, production-ready AI workloads in the cloud. NVIDIA AI experts provided hands-on support throughout the project, fostering a cycle of rapid feedback and co-learning that helped refine both P2L and the DGX Cloud platform.
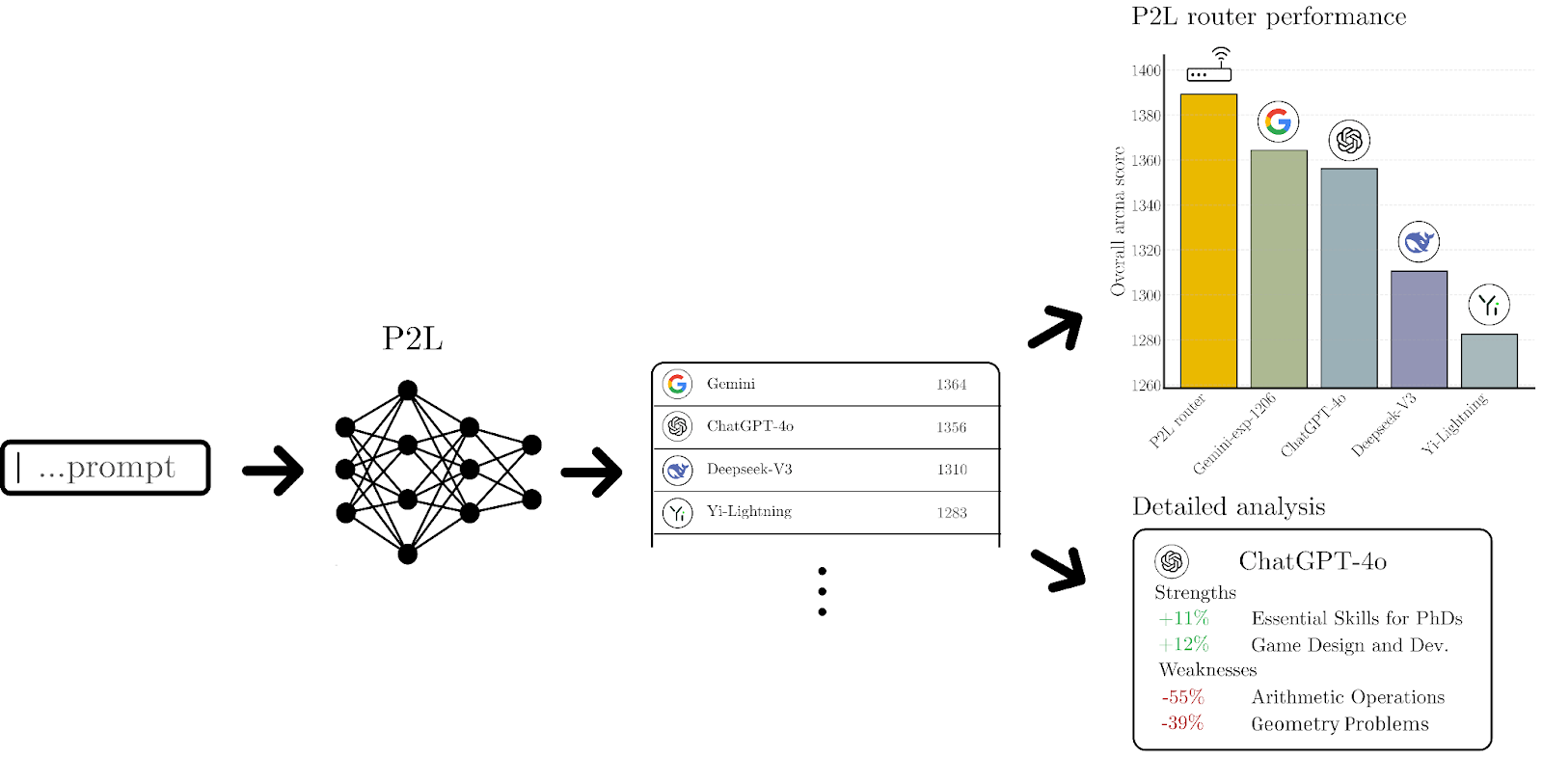
At the heart of P2L is a real-time feedback loop: Visitors compare AI-generated responses and vote for the best one, creating detailed, prompt-specific leaderboards. In essence, LMArena utilizes human ranking to train P2L, enabling it to determine the optimal outcome in terms of result quality for LLM queries.
“We wanted more than a single overall ranking,” said Evan Frick, an LMArena senior researcher and Berkeley doctoral student. “One model might excel at math but be average at writing. A single score often hides these nuances.”
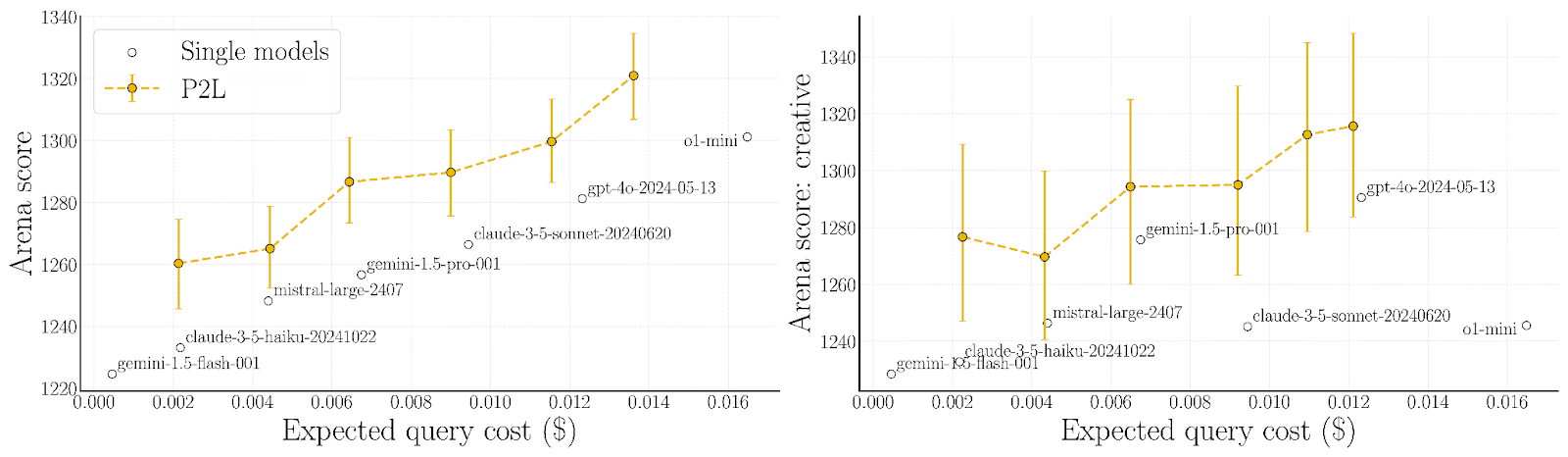
In addition to personalized leaderboards, P2L enables cost-based routing. Users can set a budget (e.g., $5 per hour), and the system will automatically select the best-performing model within that limit.
Bringing P2L to production: LMArena, Nebius, and NVIDIA
In February, LMArena deployed P2L on the NVIDIA GB200 NVL72, hosted by Nebius via NVIDIA DGX Cloud. NVIDIA and Nebius developed a shared sandbox environment to streamline onboarding, enabling early adopters to test the NVIDIA Blackwell platform with orchestration runbooks and best practices for managing multi-node topologies on NVIDIA GB200 NVL72 novel architecture.
P2L can dynamically route queries based on domain-specific accuracy and cost, which proves ideal for pushing NVIDIA GB200 NVL72’s performance boundaries.
“We built P2L so developers don’t have to guess which model is best,” Chiang said. “The data tells us which is better at math, coding, or writing. Then we route queries accordingly—sometimes factoring in cost, sometimes factoring in performance.”
NVIDIA GB200 NVL72: Flexible, scalable, developer-ready
The NVIDIA GB200 NVL72 integrates 36 Grace CPUs and 72 Blackwell GPUs, and connects them with NVIDIA NVLink and NVLink Switch for high-bandwidth, low-latency performance. Up to 30 TB of fast, unified LPDDR5X and HBM3E memory ensures efficient resource allocation for demanding AI tasks.

LMArena put the platform through its paces with consecutive training runs—first on a single node, then scaling to multiple nodes—demonstrating impressive single-node throughput and efficient horizontal scalability.
“We talk about multi-node expansions, but even a single node has kept us busy,” Chiang said. “The biggest challenge is ensuring real-time performance while letting the system adapt to constant data feedback. But that’s also the fun part.”
Open source enablement and ecosystem readiness
The DGX Cloud team worked closely with Nebius and LMArena to ensure rapid, seamless deployment for open-source developers targeting GB200 NVL72. The team validated and compiled key AI frameworks—including PyTorch, DeepSpeed, Hugging Face Transformers, Accelerate, Triton (upstream), vLLM, xFormers, torchvision, and llama.cpp—along with emerging model frameworks such as WAN2.1 video diffusion for the Arm64, CUDA 12.8+, and Blackwell environment.
This comprehensive enablement meant developers could leverage state-of-the-art, open-source tools without struggling with low-level compatibility or performance issues. The engineering effort covered compilation and optimization, containerization, orchestration best practices, and end-to-end validation of the frameworks running at scale.
The project required “deep coordination” between NVIDIA, Nebius, and LMArena, allowing developers to focus on building products rather than porting open-source libraries and components, said Paul Abruzzo, a senior engineer on the NVIDIA DGX Cloud team.
Despite tapping into GB200 NVL72 through an early access program, LMArena still achieved strong performance. It demonstrated an improvement over previous Hopper (H100) training runs, training its state-of-the-art model in just four days.
“After building and porting dependencies for GB200’s novel Arm architecture, the DGX Cloud team was able to provide the necessary open-source frameworks for this engagement, enabling rapid deployment and scale experimentation,” Abruzzo said.
This collaboration delivered not just a technical milestone for enabling AI workloads on the novel architecture of the GB200 NVL72 but a repeatable deployment model for the next generation of large-scale AI, said Andrey Korolenko, Nebius chief product and infrastructure officer. Validated frameworks, onboarding guides, and deployment blueprints now make it easier for future customers to adopt GB200 NVL72—whether at full rack scale or with more targeted sub-capacity configurations.
“Working with Nebius and NVIDIA fundamentally transformed our ability to scale P2L rapidly,” Chiang said. “The GB200 NVL72’s performance gave us the flexibility to experiment, iterate quickly, and deliver a real-time routing model that adapts to live user input. We’re seeing improved accuracy and efficiency as a result.”
Key takeaways
This deployment showcases how quickly and flexibly AI workloads can scale on the NVIDIA GB200 NVL72 platform, setting new benchmarks for speed, adaptability, and Arm64 ecosystem readiness.
- Rapid time-to-value: Four-day training of a production-scale model on NVIDIA GB200 NVL72.
- Flexible deployment: Validated both full-fabric and subcapacity use cases.
- Scalability proof point: Single-node to multi-node deployment demonstrates the ease of AI workload scalability on NVIDIA GB200 NVL72.
- Open-source ready: First time major frameworks compiled and optimized for Arm64 + CUDA on partner infrastructure.
Experience NVIDIA GB200 NVL72 at Nebius with NVIDIA DGX Cloud
To accelerate your AI innovation journey, reduce deployment complexity, and leverage cutting-edge infrastructure, NVIDIA DGX Cloud and Nebius AI Cloud are ready to replicate the successful outcomes seen with LMArena. Contact NVIDIA to learn more about deploying your workloads on GB200 NVL72 today.
And learn more about LMArena’s Prompt-to-Leaderboard (P2L) system developed on NVIDIA DGX Cloud and Nebius AI Cloud.