The NVIDIA Collective Communications Library (NCCL) implements multi-GPU and multinode communication primitives optimized for NVIDIA GPUs and networking. NCCL is a central piece of software for multi-GPU deep learning training. It handles any kind of inter-GPU communication, be it over PCI, NVIDIA NVLink, or networking. It uses advanced topology detection, optimized communication graphs, and tuning models to get the best performance straight out of the box on NVIDIA GPU platforms.
In this post, we discuss the new features and fixes released in NCCL 2.26. For more details, visit the NVIDIA/nccl GitHub repo. Note that the NCCL 2.25 release was solely focused on NVIDIA Blackwell platform support, with no library feature changes. For this reason, no release post has been published for that version.
Release highlights
NVIDIA Magnum IO NCCL is a library designed to optimize inter-GPU and multinode communication, crucial for efficient parallel computing in AI and HPC applications. The latest release of NCCL brings significant improvements to performance, monitoring, reliability, and quality of service. These improvements are supported through the following features:
- PAT optimizations: CUDA warp-level optimizations improving PAT algorithm parallelism.
- Implicit launch order: Prevent deadlocks when a device is used simultaneously by multiple communicators and detect host threads racing to launch.
- GPU kernel and network profiler support: New events allowing for more comprehensive characterization of NCCL performance at the kernel and network plugin level.
- Network plugin QoS support: Communicator-level quality of service (QoS) control, allowing users to partition available network resources across communicators.
- RAS improvements: Enriched information on collective operations, improved diagnostic output, and enhanced stability.
NCCL 2.26 features
This section dives deeper into the details of each of the following new features:
- PAT optimizations
- Implicit launch order
- GPU kernel profiler support
- Network plugin profiler support
- Network plugin QoS support
- RAS improvements
PAT optimization
This change optimizes the PAT algorithm, introduced in NCCL 2.23, by separating the computation and execution of PAT steps on different warps.
Unlike the initial implementation, where each thread would compute the PAT steps and execute them one at a time, a thread is now dedicated to computing PAT steps, and up to 16 warps can execute 16 steps in parallel coming from 16 different parallel trees.
This optimization will help in cases that have many parallel trees. That is, cases that have at least 32 ranks and small operations, and where the linear part of the algorithm starts limiting its performance; typically, at large scale.
Implicit launch order
When using multiple NCCL communicators per device, NCCL requires the user to serialize the order of all communication operations (through CUDA stream dependencies or synchronization) into a consistent total global order. Otherwise, deadlocks could ensue if the device-side communication kernels get ordered differently on different ranks.
NCCL 2.26 optionally relaxes this requirement by adding support for implicit launch order, controlled by NCCL_LAUNCH_ORDER_IMPLICIT. If enabled, NCCL adds dependencies between the launched communication kernels that ensure the device-side order matching the launch order on the host. This makes NCCL easier to use correctly but, because it increases the latency, it is off by default. Users facing difficult to debug hangs are encouraged to try it out.
Even if enabled, users must still ensure that the order of host-side launches matches for all devices. This is most easily accomplished by launching in a deterministic order from a single host thread per device. A complementary mechanism—controlled by NCCL_LAUNCH_RACE_FATAL, which is on by default—attempts to detect races between multiple host threads launching to the same device. If it triggers, the operation is aborted, and an error is returned.
GPU kernel and network profiler support
The NCCL profiler plugin interface, introduced in 2.23, now supports GPU kernel and network defined events.
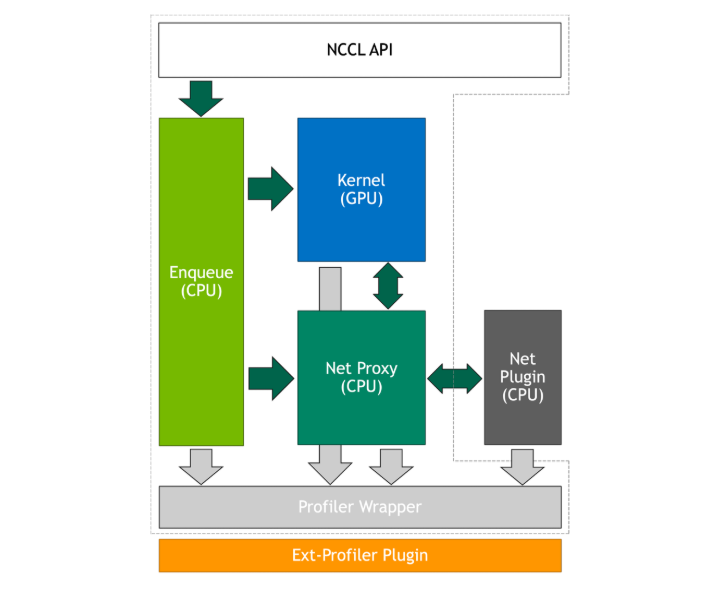
GPU kernel events
Prior to the 2.26 release, the NCCL profiler plugin interface was limited to network proxy events. However, these events only capture part of the NCCL behavior, ignoring the GPU. To address this limitation, and provide more accurate information to the profiler users, in 2.26 the NCCL core has been extended with a new kernel profiler infrastructure that allows the host code to monitor the progress of individual collective and point-to-point operations in standalone and fused kernels (that is, grouped operations).
Fused kernels generate one event per operation for every channel, allowing the profiler to directly correlate them to the originating NCCL operation.
Whenever the NCCL kernel begins or ends execution of a new operation, it communicates this to the host. Correspondingly, the host code in NCCL invokes the profiler startEvent or stopEvent callback.
The profiler plugin interface has been extended with a new ncclProfileKernelCh event that captures the kernel activity observed by the NCCL host code. This is parented by either the ncclProfileColl or ncclProfileP2p event.
It is important to note that the accuracy of the kernel events reported by NCCL is limited by the current design, which leverages the proxy thread, also used to progress network operations, to monitor the GPU kernel activity. This limitation will be addressed in future NCCL releases.
Network defined events
The NCCL profiler plugin interface, introduced in the 2.23 release, was limited to NCCL core events. However, users are often interested in the events produced by the network. To address this limitation in 2.26 the profiler plugin interface has been extended with support for network defined events. Network plugin developers can now define plugin-specific events and propagate them to the profiler plugin.
This is made possible through the following extensions in NCCL:
- New
ncclProfileNetPluginevent: Wrapper event that NCCL uses when invoking the profiler on behalf of the network plugin. - V10 network plugin interface extensions: Plumb these new events to all relevant initialization and data operation functions.
ncclResult_t (*init)(ncclDebugLogger_t logFunction,
ncclProfilerCallback_t profFunction)
ncclResult_t (*isend)(void* sendComm, void* data,
size_t size, int tag, void* mhandle,
void* phandle, void** request)
ncclResult_t (*irecv)(void* recvComm, int n, void** data,
size_t* sizes, int* tags,
void** mhandles, void** phandles,
void** request)
- NCCL core profiler callback: Used by the network plugin to invoke the profiler through NCCL.
- eHandle: Profiler plugin event handle (return value during event start, input value during event stop)
- type: Start (0) or stop (1) a network defined event
- pHandle: Pointer to NCCL core internal object, supplied by NCCL itself during isend/irecv calls and used by NCCL to link the
ncclProfileNetPluginevent to its parent during the callback - pluginId: Unique identifier used by the network and the profiler plugins to sync on the network type and event version (if the profiler plugin does not recognize the supplied pluginId it should ignore the event)
- extData: Network defined event, supplied to the profiler callback and propagated by NCCL to the profiler plugin as part of a
ncclProfileNetPluginevent
ncclResult_t (*ncclProfilerCallback_t)(void** eHandle,
int type,
void* pHandle,
int64_t pluginId,
void* extData)
The updated profiler event hierarchy accounting for kernel and network events is as follows:
ncclProfileGroup
|
+- ncclProfileColl/ncclProfileP2p
| |
| +- ncclProfileProxyOp
| | |
| | +- ncclProfileProxyStep
| | |
| | +- ncclProfileNetPlugin
| |
| +- ncclProfileKernelCh
ncclProfileProxyCtrl
Network plugin QoS support
QoS in network communication is critical to ensure good performance in HPC workloads. For example, during LLM training, several types of network communications overlap, such as pipeline parallelism (PP) and data parallelism (DP) communications. PP communications typically reside on the critical path, while DP communications do not. When these communications overlap, both experience slowdowns as they contend for shared network resources. By prioritizing communication on the critical path, the end-to-end performance of the application is significantly improved.
To enable QoS, NCCL provides a per-communicator configuration option using the ncclCommInitRankConfig API. NCCL now supports a new trafficClass field in the existing ncclConfig_t structure. The trafficClass is an integer that serves as an abstract representation of the QoS level for communicator network traffic. Applications can set this field using either a default value or a user-defined setting. The specific meaning of the trafficClass is determined by the network system administrator and the network stack implementor.
struct {
...
int splitShare;
int trafficClass; // add trafficClass to communicator
} ncclConfig_t
NCCL passes the trafficClass to the network plugin without modifying it
The network plugin interface is also extended with a new ncclNetCommConfig_t structure, which encompasses the trafficClass and is passed to each connection in the network plugin. For instance, the connect function adds an input argument ncclNetCommConfig_t* config.
struct {
int trafficClass; // Plugin-specifig trafficClass value
} ncclNetCommConfig_t
ncclResult_t (*connect)(int dev, ncclNetCommConfig_t* config, void* handle, void** sendComm, ncclNetDeviceHandle_v10_t** sendDevComm);
Network plugin implementors can use the trafficClass value to set specific fields in their network packets to enable QoS. The extended plugin interface is designed to support both internal and external network plugins. For example, the value can be passed to the NCCL internal net_ib plugin, where it can be used to configure the qpAttr.ah_attr.grh.traffic_class field if the trafficClass is defined.
RAS Improvements
The bulk of changes to the RAS subsystem for this release were internal enhancements to improve its stability and memory footprint at scale. User-visible improvements include:
- Report mismatches in collective operation counts separately for each operation type. This may help identify nondeterministic launch order scenarios.
- Provide details about communicator ranks that failed to report in. Prior to 2.26, only the rank number was provided in such cases, and RAS could not reliably determine if the lack of information from a rank was due to that rank being unreachable or simply because the rank was no longer a given communicator’s member. These two cases can now be distinguished, with the former reported as an
INCOMPLETEerror, and the latter as aMISMATCHwarning with a newNOCOMMrank status (replacing the previously usedUNKNOWN).
RAS-specific fixes include:
- Avoid counting graph-captured collectives. Depending on the collective algorithm being used, some graph-captured collective operation could result in the collective operation counts going out of sync between ranks, resulting in false-positive warnings from RAS. The counting of graph-captured collectives has been disabled for now.
- Clean up RAS resources prior to termination. This not only avoids additional noise from various third-party leak-detection tools but also, in case of the libnccl.so library being dynamically unloaded without terminating the process, avoids a crash when the still running RAS thread would try to execute code that had been unmapped.
Bug fixes and minor features
NCCL 2.26 provides the following additional updates:
- Add Direct NIC support (GPUDirect RDMA for NICs attached to a CPU if the GPU is connected to the CPU through C2C, controlled through
NCCL_NET_GDR_C2C) - Add timestamps to NCCL diagnostic messages (on by default for WARN messages; configurable through
NCCL_DEBUG_TIMESTAMP_LEVELSandNCCL_DEBUG_TIMESTAMP_FORMAT) - Reduce the memory usage with NVLink SHARP
- Incorporate performance data for Intel Emerald Rapids and Sapphire Rapids CPUs into the NCCL performance model
- Add support for comment lines (starting with #) in the nccl.conf file
- Fixed a race condition with split-shared communicators during connection establishment
- Fixed a performance regression where
NCCL_CROSS_NIC=1would still alternate rings, breaking the rings GPU-NIC associations - Improved IB/RoCE GID detection in container environments
- Fixed a race condition with non-blocking communication, where back-to-back collective operations on different communicators could result in a crash
- Fixed a bug on B203 where NCCL requested more shared memory than the device supports
- Fixed a hang caused by the progress thread spinning on network progress when users abort communicator
- Fixed a hang when the network plugin’s test call returns an error
- Fixed a hang when mixing different architectures, where ranks could end up with different communication patterns
- Fixed a double-free crash on failed
ncclCommInitRankandncclCommFinalize - Fixed a bug where under rare circumstances some variables specified in the config file could be ignored
Summary
NCCL 2.26 introduces several important new features and improvements, including PAT optimizations, implicit launch ordering, GPU kernel profiler support, network plugin profiler support, network plugin QoS support, and RAS improvements.
To learn more about previous NCCL releases, see the following posts:
Learn more about NCCL and NVIDIA Magnum IO. And check out the on-demand session NCCL: The Inter-GPU Communication Library Powering Multi-GPU AI | GTC 25 2025 | NVIDIA On-Demand