NVIDIA designed the NVIDIA Grace CPU to be a new kind of high-performance, data center CPU—one built to deliver breakthrough energy efficiency and optimized for performance at data center scale.
Accelerated computing is enabling giant leaps in performance and energy efficiency compared to traditional CPU computing. To deliver these speedups, full-stack innovation at data center scale is required, spanning chips, systems, software, and algorithms. Choosing the right architecture for the right workload with the best energy-efficient performance is critical to maximizing the performance and minimizing the footprint of your data center.
As workloads are increasingly accelerated, there remain use cases that today primarily run on traditional CPUs—particularly code that is sparse and “branchy” serialized tasks such as graph analytics. At the same time, data centers are increasingly power-constrained, limiting the growth of their capabilities. This means that all workloads that can be accelerated should be accelerated. Those that cannot be accelerated must be run on the most efficient compute possible, and the CPU must be optimized for those workloads.
The new, energy-efficient Grace CPU requires outstanding single-thread performance, as well as enough cores to run many applications simultaneously. Those cores each require significant memory bandwidth to ensure high CPU core utilization and the ability to communicate with each other quickly and efficiently.
Designed for greater energy efficiency with no performance compromise
NVIDIA Grace architecture is designed for an accelerated computing world in which GPUs and coherently coupled CPU-GPU architectures accelerate the data center. Such architectures require a CPU with outstanding single-thread performance, a fast fabric, exceptional energy efficiency, and high memory bandwidth.
The NVIDIA Grace CPU combines 72 high-performance and energy-efficient Arm Neoverse V2 cores cores, connected with the NVIDIA Scalable Coherency Fabric (SCF). The NVIDIA SCF is a high-bandwidth, on-chip fabric that provides a total of 3.2 TB/s of bisection bandwidth—double that of traditional CPUs. A high-bandwidth on-chip fabric is needed to deliver maximum system-level performance by maintaining the data flow among CPU cores, cache, memory, and system input and output. Traditional CPUs with a chiplet architecture are less energy efficient and have area and communication overhead that provides less predictable performance.
Grace is the first data center CPU to use high-speed LPDDR5X memory with server-class reliability through mechanisms like error-correcting code (ECC). By using this more efficient memory type and a wide memory subsystem, Grace delivers up to 500 GB/s of memory bandwidth while consuming just one-fifth the energy of traditional DDR memory at similar cost.
These numerous innovations mean that the NVIDIA Grace CPU Superchip delivers outstanding performance, memory bandwidth, and data-movement capabilities with breakthrough performance per watt. At the data center level, this translates into a generational leap in performance and outstanding total cost of ownership (TCO). Grace architecture delivers these benefits in a data center grade, general-purpose CPU, which means that it provides versatility and performance across a broad range of foundational data center workloads such as microservices, data analytics, graph analytics, and simulation.

Figure 1 compares the raw performance per server between NVIDIA Grace architecture and leading x86 servers and shows that it delivers leading server level performance against the best of the x86 competition.
The exceptional memory bandwidth and fabric performance of the Grace architecture make it strong across several types of popular applications, including:
- Microservices: Small, independent services that help data centers scale easily and manage individual services without affecting the entire application. The Google protocol buffers workload tested measures how quickly data can be serialized and parsed to be exchanged between microservices.
- High-performance computing (HPC) and data analytics: Workloads such as weather forecasting and Hi-Bench K-means Spark are highly sensitive to achievable memory bandwidth. The leading memory bandwidth and fast NVIDIA designed fabric enables Grace to deliver best-in-class performance on these benchmarks.
- Graph analytics: Commonly used as part of optimization algorithms, fraud detection and social network analyses in financial services, healthcare, and marketing and operations in many industries. In the GapBS Breadth First Search benchmark, Grace—which has twice the fabric bandwidth of traditional x86 CPUs—stands out compared to the competition. Control flows expand to all available CPU cores and then back down to a single CPU core, benefiting from fast communication between CPU cores.
On workloads such as compression that scale well with cores, Grace can perform similarly to higher core count products, with the high-performance cores and high-bandwidth NVIDIA SCF.
Figure 2 shows the energy efficiency of those servers. With its low-power and high-bandwidth memory, Grace delivers 2x more performance for the same power envelope as the competition across the full spectrum of workloads.
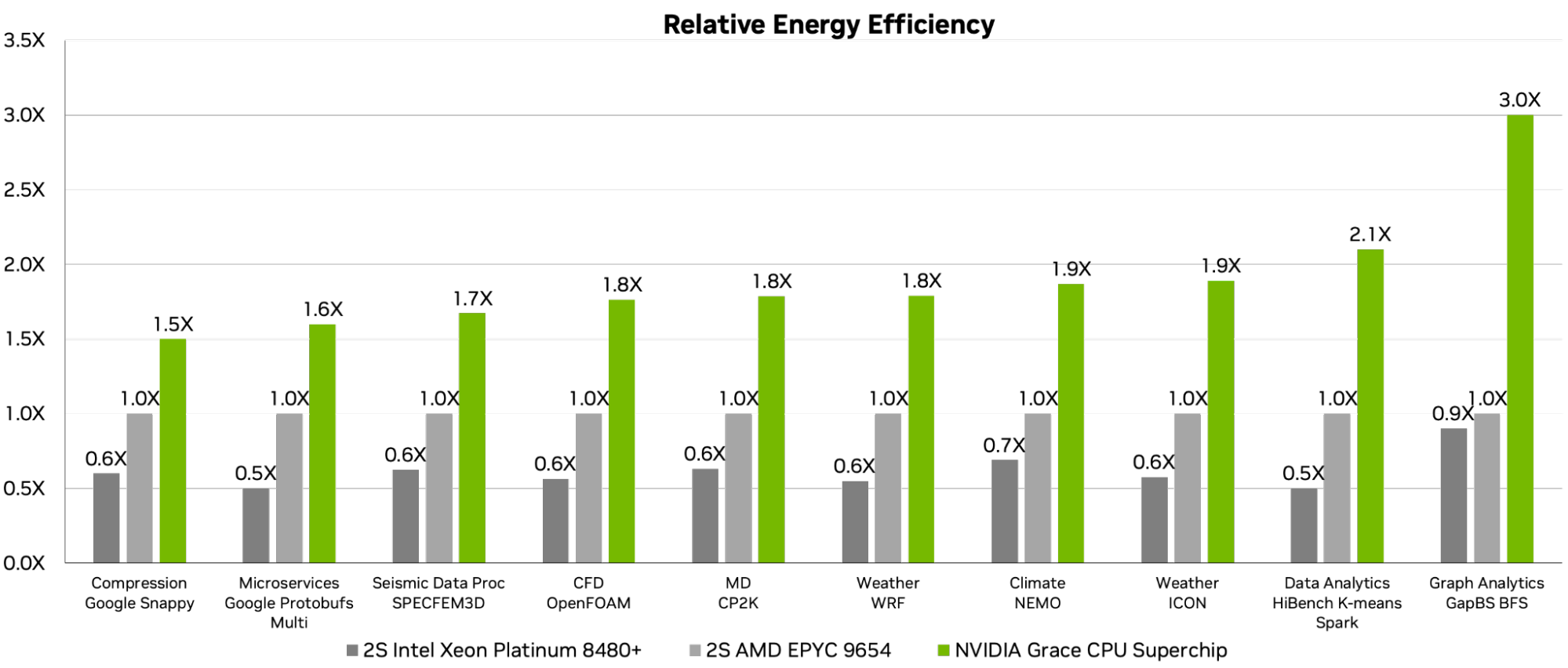
NVIDIA Grace Superchip 480GB of LPDDR5X, AMD EPYC 9654 768 GB of DDR5, and Intel Xeon Platinum 8480+ with 1TB DDR5. OS: Ubuntu 22.04 Compilers: GCC 12.3 unless noted below. Power for energy efficiency includes CPU + memory measured power.
Compression: Snappy (Commit af720f9a3b2c831f173b6074961737516f2d3a46 | N instances in parallel) Microservices: Google Protobufs (Commit 7cd0b6fbf1643943560d8a9fe553fd206190b27f | N instances in parallel) Seismic Data Proc: SPECFEM3D four_material_simple_model; HPC SDK 24.3 CFD: OpenFOAM Motorbike | Large v2212 MD: CP2K RPA 2023.1 Weather: WRF CONUS12km x86: ICC 2024.01; Climate: NEMO Gyre_Pisces v4.2.0 Weather: ICON QUBICC 80 km resolution Data Analytics: HiBench+K-means Spark (HiBench 7.1.1, Hadoop 3.3.3, Spark 3.3.0; Grace: NVHPC 24.5, x86: Intel 2021.4) Graph Analytics: The Gap Benchmarks Suite BFS arXiv:1508.03619 [cs.DC], 2015.
NVIDIA Grace delivers consistent performance
Beyond its exceptional performance and energy efficiency, the Grace CPU is designed to sustain consistent performance levels with deterministic performance. Grace can maintain maximum frequency even when all cores are active and deliver high levels of performance even when power is reduced.
The NVIDIA SCF removes data movement bottlenecks. By combining a high-bandwidth fabric and a wide LPDDR5X memory interface, the Grace CPU achieves over 90% STREAM efficiency (a measure of delivered memory bandwidth relative to peak-rated bandwidth) even when all cores are active. In contrast, competitive systems will reach just over 80% max efficiency, dropping to around 70% when all cores are active (Figure 3).
The Grace CPU enables use of the optimal number of CPU cores while ensuring each core can fully utilize the available memory bandwidth. As a result, Grace delivers leading performance in memory bandwidth-bound workloads including weather forecasting or data analytics (Figure 1).
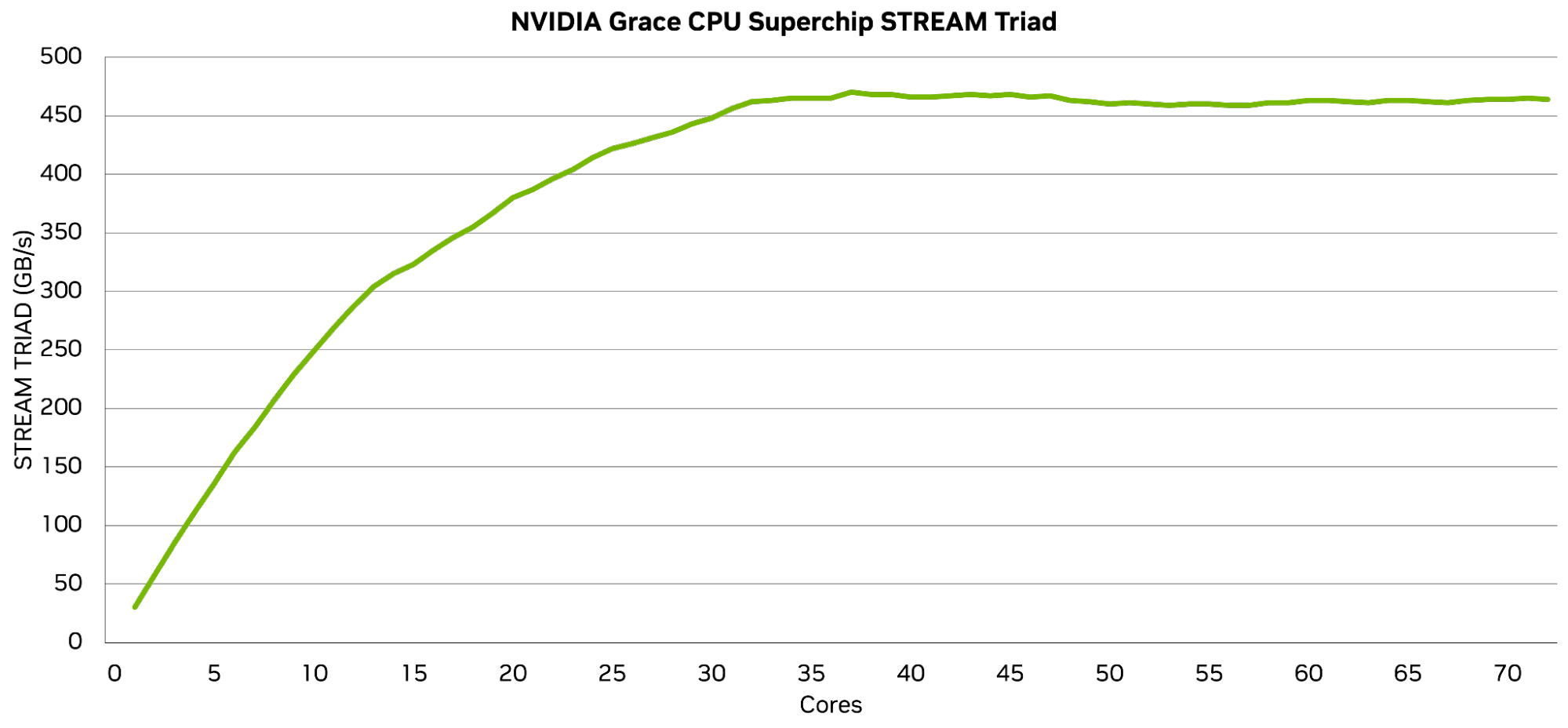
Competitive comparison from High Performance Tuning Guide for AMD EPYC 9004 Series Processors using STREAM Triad results on a system with 2x 9654 and 1 DPC (DIMM Per Channel), with DDR5-4800 Dual-Rank DIMMs.
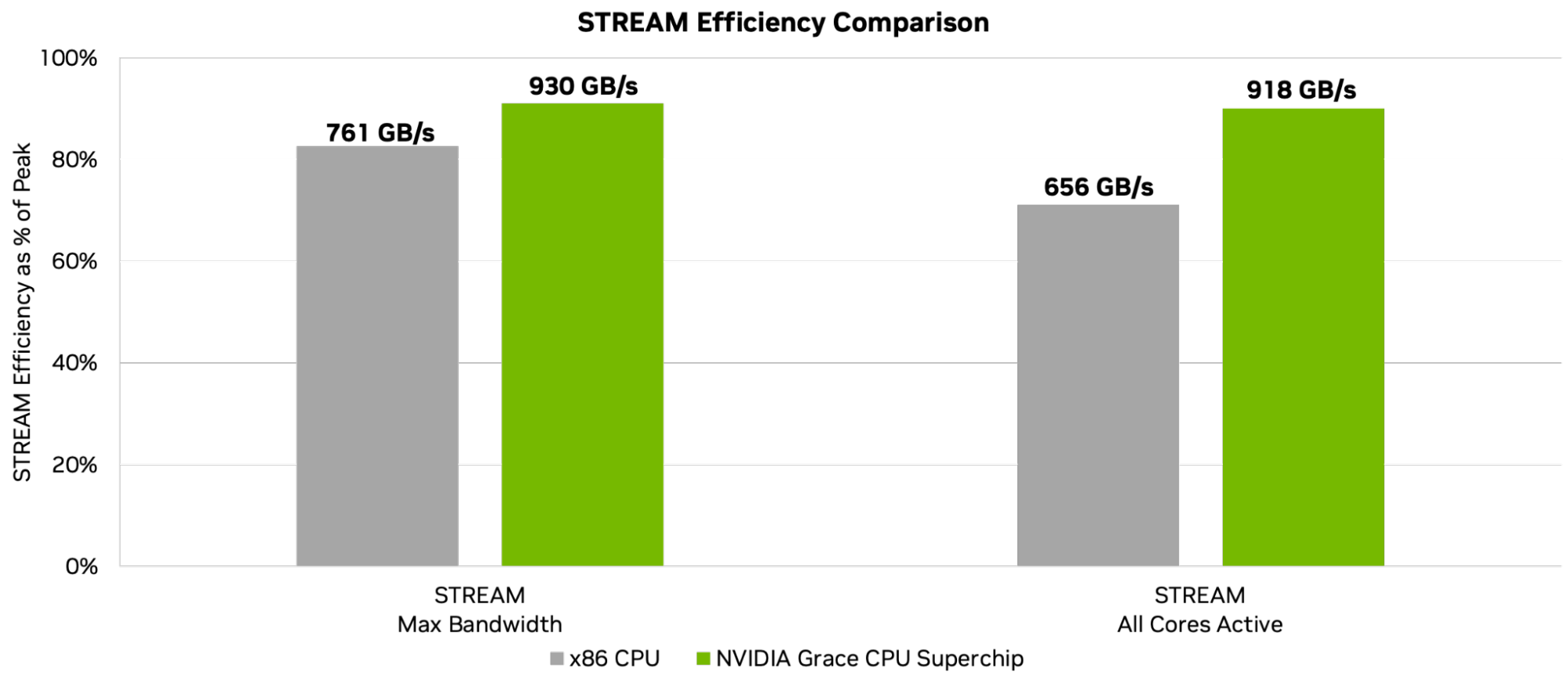
NVIDIA Grace CPU Superchip 480GB of LPDDR5X. OS: Ubuntu 22.04 Compilers: GCC 12.3.
Competitive comparison from High Performance Tuning Guide for AMD EPYC 9004 Series Processors using STREAM Triad results on a system with 2x 9654 and 1 DPC (DIMM Per Channel), with DDR5-4800 Dual-Rank DIMMs.
Unmatched levels of data center performance
In today’s post-Moore’s Law era, traditional CPU methods of meeting the insatiable demand for computing performance require disproportionate increases in cost and energy. Data centers are becoming constrained in power delivery, limiting the growth of their capabilities. To meet these challenges and bolster sustainable computing goals, modern data centers must accelerate all workloads. Workloads that cannot be accelerated must use the most energy-efficient computing available.
NVIDIA Grace meets these challenges with the ability to deliver twice the performance in the same power, opening new opportunities for optimizing your data center. Data center operators have the option of doubling the performance in the same power envelope, or maintaining a consistent level of performance in only half the energy. This opens the potential to use those power savings for acceleration with GPUs in a limited power budget.
NVIDIA Grace is built using Arm standards. This means that any work done transitioning to other Arm data center class architectures will run on Grace, and any work done on NVIDIA Grace will work on the rest of the Arm data center ecosystem. Transitioning to NVIDIA Grace also enables tightly coupled CPU and GPU architectures with products such as the NVIDIA GB200 Grace Blackwell Superchip in the NVIDIA GB200 NVL72. With Grace, data centers can standardize on a single CPU architecture that also works across the entire Arm ecosystem.
Ready to get started? Try the free hands-on NVIDIA Grace CPU lab through NVIDIA LaunchPad.