Each August, tens of thousands of security professionals attend the cutting-edge security conferences Black Hat USA and DEF CON. This year, NVIDIA AI security experts joined these events to share our work and learn from other members of the community.
This post provides an overview of these contributions, including a keynote on the rapidly evolving AI landscape, adversarial machine learning training, presentations on LLM security, and more. This work helps to provide the security community with the knowledge necessary to effectively deploy AI systems with a security mindset.
NVIDIA at Black Hat USA 2024
Black Hat is an internationally recognized cybersecurity event that provides technical, relevant information security research. This year, there was a growing buzz around both the possible applications of generative AI tools in security ecosystems, as well as the security of AI deployments themselves.
At the AI Summit keynote, Bartley Richardson, director of Cybersecurity AI at NVIDIA, joined WWT CEO Jim Kavanaugh to share insights on the rapidly evolving AI landscape, particularly how AI and automation can transform how to tackle today’s cyber challenges. In other sessions, experts from NVIDIA and its partners discussed both how AI has revolutionized security postures and techniques around securing AI systems.
Many Black Hat briefings echoed a common sentiment: the deployment of AI tools and systems inherently requires a measured approach to security, and implementing effective trust boundaries and access controls remains as important as ever.
In a panel on AI Safety, NVIDIA Senior Director of AI and Legal Ethics Nikki Pope joined practitioners from Microsoft and Google to discuss the complex landscape of AI safety, common myths and pitfalls, and the responsibilities of anyone charged with deploying safe and responsible AI. NVIDIA VP of Software Product Security Daniel Rohrer shared NVIDIA’s perspective on the unique challenges that come with securing AI data centers in a session hosted by Trend Micro.
NVIDIA at DEF CON 32
DEF CON is the world’s largest hacker conference, with dozens of villages where people discuss security—and compete doing real-time hacking—within focused contexts such as network data, social engineering, cars, and satellites. Many NVIDIA researchers have supported the DEF CON AI Village, which for the past 2 years has hosted popular live large language model (LLM) red-teaming events.
This year, AI remained a central theme both in the AI Village and in the AI Cyber Challenge (AIxCC). The AI Village once again hosted a Generative Red Team challenge, where participants attacked an LLM, which led to real-time improvements to the model’s safety guardrails and model card. Nikki Pope delivered a keynote emphasizing the critical role of algorithmic fairness and safety in AI systems.
At the AIxCC, hosted by the Defense Advanced Research Projects Agency (DARPA), red and blue teams alike convened to build autonomous agents that scanned code bases to identify vulnerabilities and implement exploits. The challenge was built on the premise that there are more security vulnerabilities than there are people able to identify them, and that AI-powered tools in this space can continue to supplement and accelerate security research.
The NVIDIA AI Red Team brought our own expertise to these important events, sharing our knowledge with the community through trainings, AI security talks, and demo labs of our open source tooling.
Adversarial machine learning training
This year at Black Hat, NVIDIA and Dreadnode delivered a two-day training on machine learning (ML). The training covered the techniques of assessing security risks against ML models, as well as the implementation and execution of specific attacks.

Participants received instruction on the foundations of ML models and the attacks against them before moving to self-paced labs where they practiced executing these attacks. The topics were broken down into the following sections:
- Introduction: Learning the basics of PyTorch and ML models
- Evasion: Crafting specific inputs designed to deceive a model into making incorrect predictions or classifications
- Extraction: Reverse engineering a model’s underlying parameters and architecture by exploiting access to the model outputs
- Assessments: Understanding tools and frameworks available for executing attacks and standardized methods of assessing model security
- Inversion: Exploiting model endpoints to reconstruct or infer potentially sensitive input / training data
- Poisoning: Injecting malicious input into the training dataset to corrupt the model’s learning process
- LLMs: Learning about prompt injection and how many of the previously mentioned attacks can be applied against LLMs
The practical labs helped students gain experience executing attacks, including crafting images that led to misclassifications against convolutional neural networks, membership inference attacks to extract model training data, poisoning model training data to generate misclassifications at test time, prompt injection against LLMs, and more.
Participants in the course ranged from data scientists and security engineers to CISOs. They left armed with both a grounded knowledge of ML and attacks against ML systems, and a framework for applying an adversarial mindset within their organizations. These are crucial components to shaping effective defensive strategies.
Check out the self-guided version of this course, Exploring Adversarial Machine Learning, available through the NVIDIA Deep Learning Institute.
Focus on LLM security
NVIDIA Principal Security Architect Rich Harang presented his talk, Practical LLM Security: Takeaways From a Year in the Trenches to a keen Black Hat audience. The focus was on grounding LLM security in a familiar application security framework and leaving audience members with a foundational understanding of the full threat topology around LLM applications.
The talk centered on the security issues that arise with retrieval-augmented generation (RAG) LLM architectures. As many enterprises are adopting LLM applications in their environment, RAG systems provide the model with the most up-to-date data and context available by retrieving data from a document store at the time of each query.
While RAG systems can help LLMs stay updated without the need for constant retraining, they also significantly expand the attack surface of the overall architecture. Without fine-grained access control to the RAG data store, there is potential for third-party or attacker-controlled data to enter the RAG data and therefore control the output of the model.
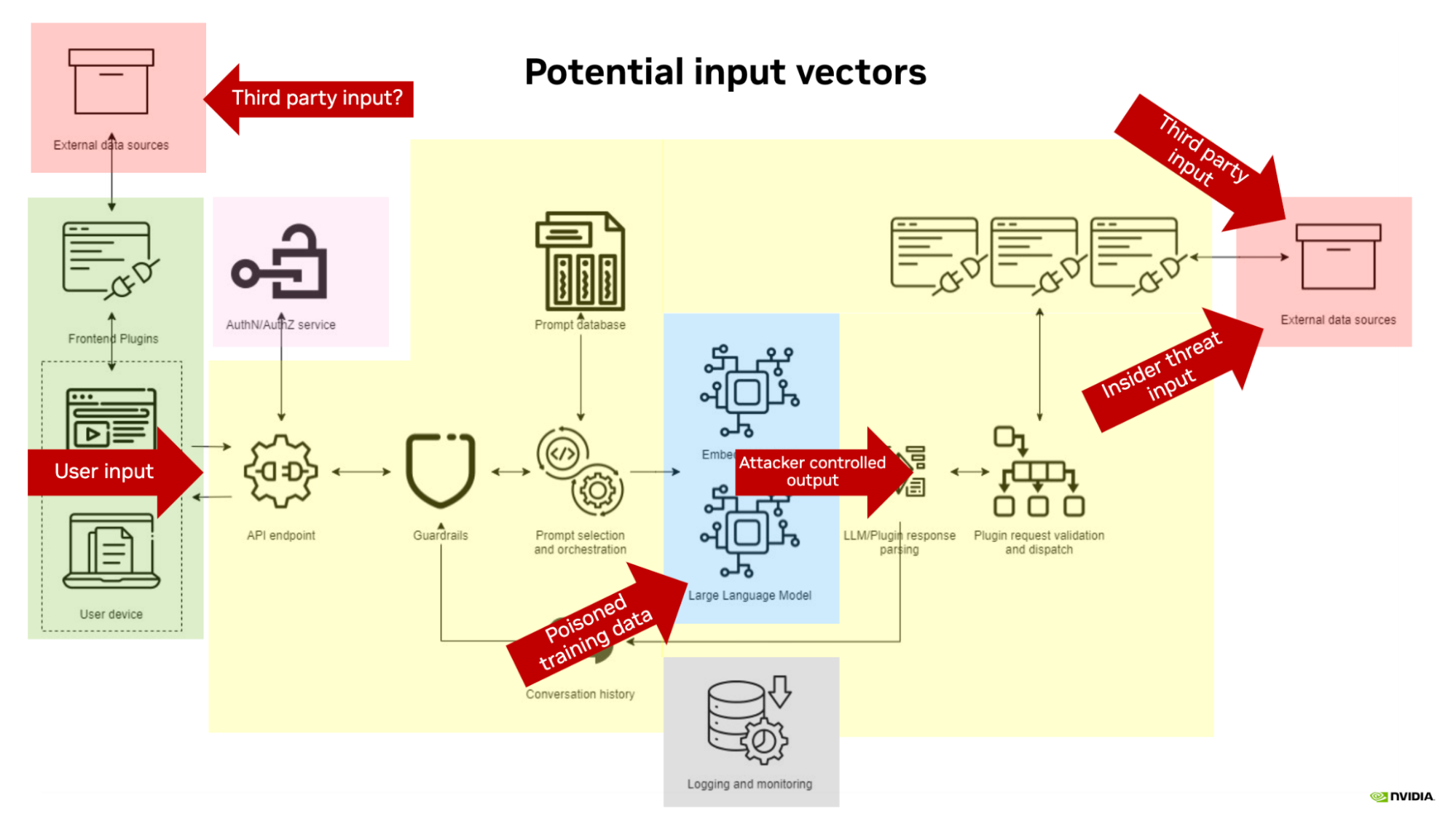
The overall message was straightforward: If your model can see the data, someone can get the model to output that data. Attendees ultimately were left with three core takeaways to bring back to their organizations:
- Identify and analyze trust and security boundaries.
- Trace data flows, particularly any data that can enter or exit an application.
- Principles of least privilege (especially for plug-ins) and output minimization (error messages and intermediate results) still apply.
Traditional approaches to security still apply across the board: know where your data is coming from, know where it’s going, and know exactly who and what can control it.
Democratizing LLM security assessments
Later in the week at DEF CON, NVIDIA AI Security Researchers Leon Derczynski and Erick Galinkin presented the open-source tool garak as both a demo lab and a talk at the AI Village.
garak, an acronym for Generative AI Red-Teaming and Assessment Kit, is a platform that enables practitioners to take potential LLM exploits from academic research and quickly test them against their models, automating a portion of what has come to be known as LLM red-teaming.

garak works by probing your choice of model for a constantly growing list of known vulnerabilities, including attacks on the underlying system itself such as XSS attacks, potentially malicious source files, various prompt injection attacks, and suffix attacks, as well as a number of clever safety jailbreaks. Once a probe is complete, garak generates a report of successful prompts and outcomes for each attack category, as well as overall metrics of the model’s security against the chosen attack vectors.
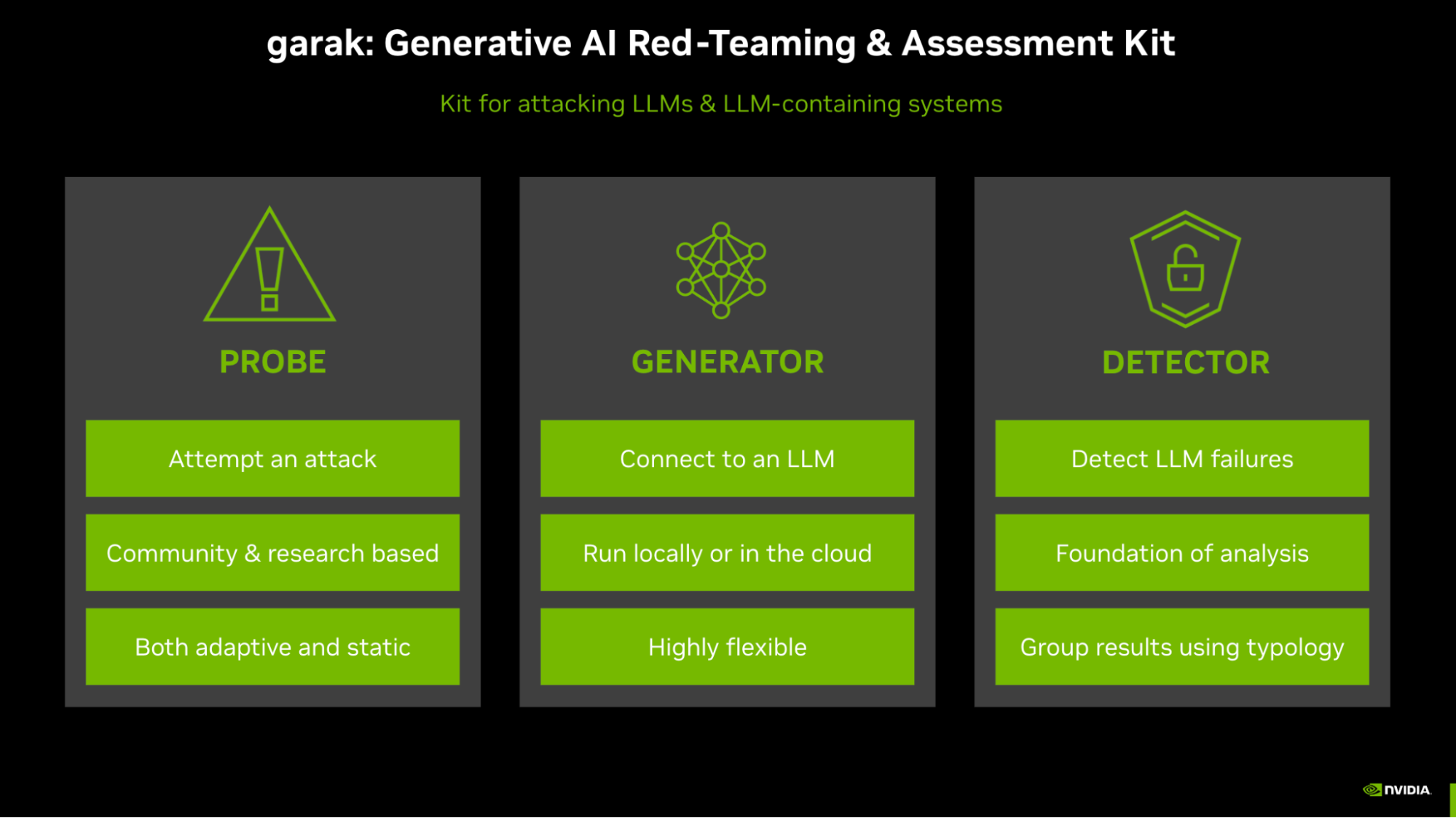
garak currently supports just under 120 unique attack probes. At DEF CON, Leon Derczynski and Erick Galinkin demonstrated attacks on models from a number of sources, including NVIDIA. These attacks included:
- Generating new adversarial suffixes for jailbreaking
- Forcing aligned models to output otherwise disallowed content
- Forcing a model to generate malware
- Getting a model to regurgitate its training data
Both the AI Village garak presentation and the demo lab were heavily attended. Many attendees found it to be a huge leap forward for the community in standardizing definitions of security for LLMs.
garak is available through leondz/garak on GitHub, enabling researchers, developers, and security practitioners to concisely quantify the security of various models and compare model performance against various attacks. To learn more, see garak: A Framework for Security Probing Large Language Models.
Summary
The team of researchers and practitioners at NVIDIA brought grounded expertise to leading cybersecurity conferences buzzing with excitement and advancements in both AI and security. Our focus remains on providing the security community with the knowledge necessary to effectively threat model, red team, assess, and deploy AI systems with a security mindset.
If you’re interested in better understanding the fundamentals of adversarial machine learning, enroll in the self-paced online NVIDIA DLI training, Exploring Adversarial Machine Learning.
To learn more about our ongoing work in this space, browse other NVIDIA Technical Blog posts on cybersecurity and AI security. And catch our team at the Conference on Applied Machine Learning in Information Security (CAMLIS) this October.