Reservoir simulation helps reservoir engineers optimize their resource exploration approach by simulating complex scenarios and comparing with real-world field data. This extends to simulation of depleted reservoirs that could be repurposed for carbon storage from operations. Reservoir simulation is crucial for energy companies aiming to enhance operational efficiency in exploration and production.
This post demonstrates how the NVIDIA Grace CPU excels in solving linear systems within this workflow, with Petrobras achieving up to 4.5x faster time-to-solution, 4.3x greater energy efficiency, and 1.5x higher scalability compared to alternative x86-based CPUs.
Petrobras is a leading Brazilian energy company transitioning to new energy sources while maintaining its core oil and gas (O&G) exploration and production business. According to the Top500 and Green500 lists, Petrobras has the largest HPC infrastructure in Latin America, powered by the NVIDIA full-stack accelerated computing platform. Their primary workloads are seismic processing and reservoir simulation.
The company pioneered ultra-deepwater exploration with operations reaching depths up to 7 km. With a single well drill costing up to $100 million, high-performance computing (HPC) helps reduce resource exploration uncertainty and improve production success rates.
Reservoir simulation and the SolverBR project
Solving linear systems is the most time-consuming task in reservoir simulations (Figure 1). This process can account for up to 70% of the total computational time within the Petrobras simulation pipeline. Therefore, optimizing sparse linear solvers for performance and maintaining high accuracy is crucial for reliable reservoir studies.
Petrobras collaborated with UFRJ and other innovative research institutes in Brazil to develop SolverBR, a CPU-based linear equations solver that uses novel compute parallelization techniques with an efficient multicore implementation. SolverBR is integrated into proprietary geomechanical and third-party flow simulators, including Computer Modelling Group (CMG) IMEX and GEM, widely used for compositional simulation of pre-salt reserves.

Porting SolverBR from x86 to Arm
Arm-based processors such as the NVIDIA Grace CPU are gaining momentum in HPC applications, including in the energy industry. Petrobras, NVIDIA, and Brazil’s CESAR Innovation Center are partnering to port and benchmark SolverBR to the NVIDIA Grace CPU in an initiative to measure the main benefits of Arm-based CPUs.
The NVIDIA Grace CPU has 72-core Arm Neoverse V2, connected by a high-bandwidth NVIDIA scalable coherency fabric and paired with high-bandwidth and low-power double data rate 5x (LPDDR5X) memory.
Initial results demonstrated that NVIDIA Grace delivers best-in-class performance ratios across time-to-solution (TTS) and estimated energy-to-solution (ETS), compared to x86-based flagship processors available on-premises and in the cloud.
The project focuses on maintaining a multiplatform build system, enabling a single codebase and compilation scripts to work seamlessly across various platforms. This ensures consistent testing and reliable performance comparisons when porting the x86 codebase to Arm with minimal required effort. The Arm ecosystem robust open-source compilers and debuggers have significantly facilitated this transition.
GCC 12.3 was chosen as the test compiler due to its excellent performance. GCC 12.3 or above is recommended due to its tuning support for the Arm Neoverse V2 core. The porting to Arm process involved a few simple steps:
- Removal of all x86 architecture-specific flags, such as
-maxv,-march, and-mtune, which have different meanings in Arm. - Use the
-O3optimization level to trigger optimization steps such as function inlining, vectorization, loop unrolling, interchange, and fusion. For even more performance, consider-Ofast. - Append the
-mcpu=nativeto CFLAGS to ensure the compiler auto-detects the build system’s CPU. - Finally, use
-fltoas an optional flag for link-time optimization. Depending on the application,-fsigned-charor-funsigned-charmay also be required.
Minimal effort was taken to address compilation errors by replacing Intel Intrinsics functions with Arm-specific functions using the header-only library sse2neon. Runtime errors were fixed, including memory synchronization issues caused by specific compiler optimizations, which resulted in instruction reordering and subsequent floating-point precision divergencies.
For this initial experiment, Petrobras used a fixed set of compilation flags for each architecture (x86_64 and aarch64) without implementing processor-specific tuning. The goal is to comprehend the performance behavior out-of-the-box. Table 1 illustrates the compilation flags employed.
| Architecture | Compiler flags |
| x86_64 | -std=c++17 -O3 -lrt -fPIC -m64 -march=native -mtune=native -fopenmp-simd -fopenmp |
| aarch64 | -std=c++17 -O3 -lrt –fPIC -mcpu=native -fopenmp-simd -fopen |
Measuring performance and energy efficiency
Singularity containers were employed to replicate the SolverBR computing stack across various platforms to ensure reproducibility. A single definition file was utilized to generate multiple runtime containers, resulting in unique .sif files, one for each CPU architecture. Table 2 specifies all the tested CPUs, both x86-based and Arm-based, on-premises and in the cloud. NVIDIA conducted the experiments on the Grace architecture, while Petrobras and CESAR executed the benchmarks on the remaining architectures.
| Environment | Processor | Architecture | Physical cores |
| On-premises | Intel Xeon Gold 6248* | x86_64 | 20 |
| On-premises | NVIDIA Grace CPU** | Armv9 | 72 |
| AWS EC2 R7g | AWS Graviton3 | Armv8 | 64 |
| AWS EC2 R7i | Intel Xeon Platinum 8488C (Sapphire Rapids) | x86_64 | 48 |
| AWS EC2 R7a | AMD EPYC 9R14 (Genoa) |
x86_64 | 96 |
*Intel Xeon Gold 6248 is the main on-premises CPU cluster at Petrobras Research Center (CENPES)
**NVIDIA Grace CPU data computed on a single NVIDIA Grace SoC using the GH200 Superchip platform
Testing the linear portion of the reservoir simulation pipeline shown in Figure 1 involved extracting the CMG-generated sparse matrices from pre-salt oil and gas field datasets (Búzios, Proxy 100, Proxy 200, Sapinhoá) and the SPE10 benchmark model. The example establishes how CMG simulators can be modularized and extended with third-party components or software. CMG engineers are currently exploring additional opportunities to port components and capabilities of their simulators, aiming to optimize performance across various platforms and hardware architectures.
Figure 2 displays the linear methods configurations: Adaptive Implicit Method (AIM), Krylov Subspace Projection Generalized Minimal Residual (KSPGMRES), Constrained Pressure Residual (CPR), Domain Decomposition (DD), Incomplete LU Factorization (ILU). Each system of equations was solved 50 times for all models across 3 years, resulting in thousands of executions.
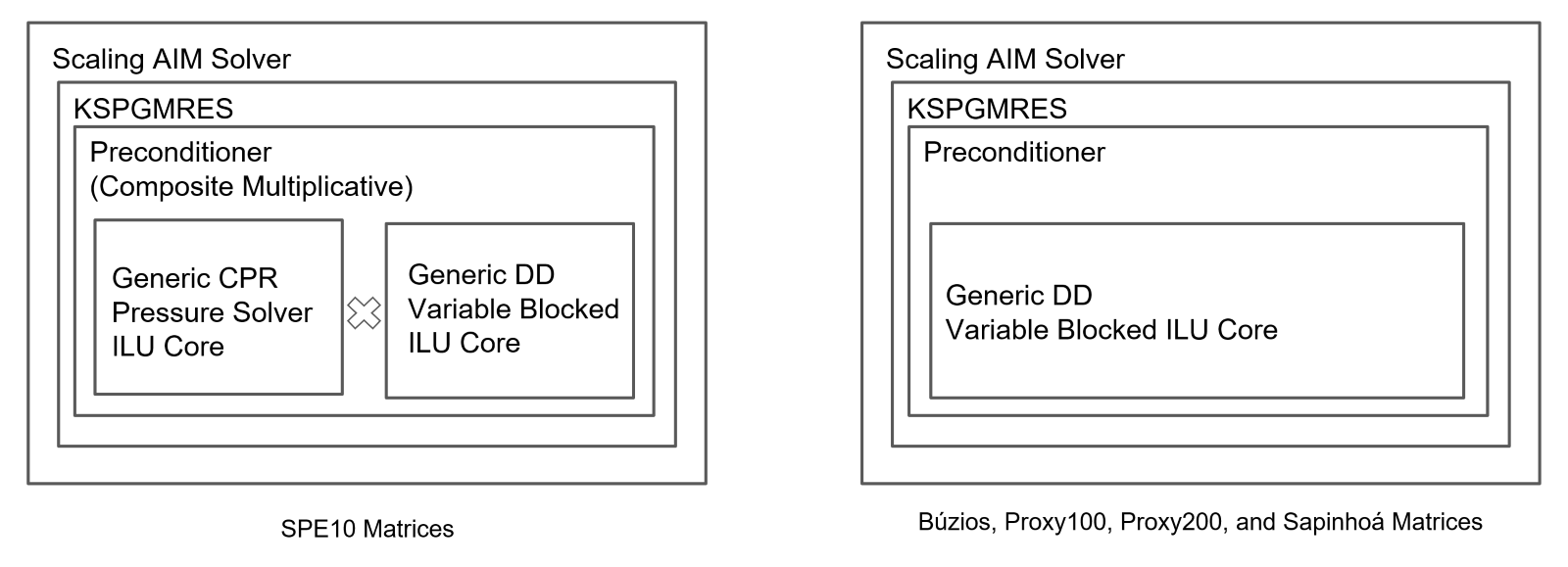
Figure 3 presents the speedup results for each model, utilizing the maximum available cores in single-socket processors. Petrobras currently uses the Intel Xeon Gold 6248 platform in its on-premises production CPU cluster, which serves as the reference point for results normalization.
The NVIDIA Grace architecture demonstrates superior performance, achieving the highest performance ratios across all models, including:
- Up to 4.5x speedup over Intel Xeon Gold 6248 (Petrobras baseline CPU)
- Up to 2.9x speedup over Intel Xeon Platinum 8488C
- Up to 1.9x speedup over AMD EPYC 9R14
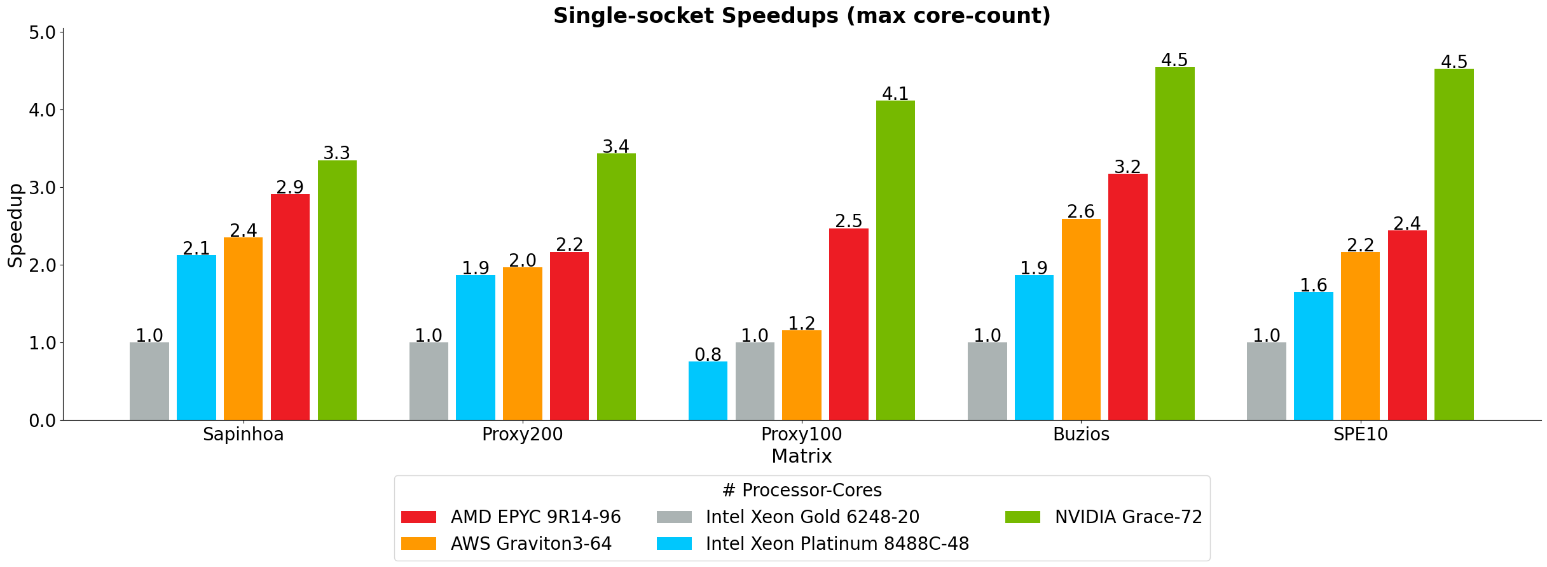
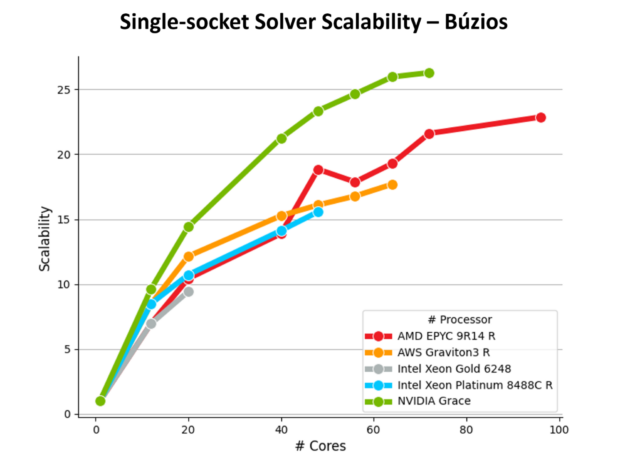
Figure 4 shows leading scalability for the NVIDIA Grace CPU when varying the total number of cores up to the maximum for each single-socket processor, up to 53% over the least scalable option. The NVIDIA Grace CPU demonstrates exceptional performance for this specific workload due to its unique characteristics, which include high effective memory bandwidth, an advanced CPU Scalable Coherent Fabric (NVIDIA SCF), and the adoption of server-class Arm Neoverse V2 cores.
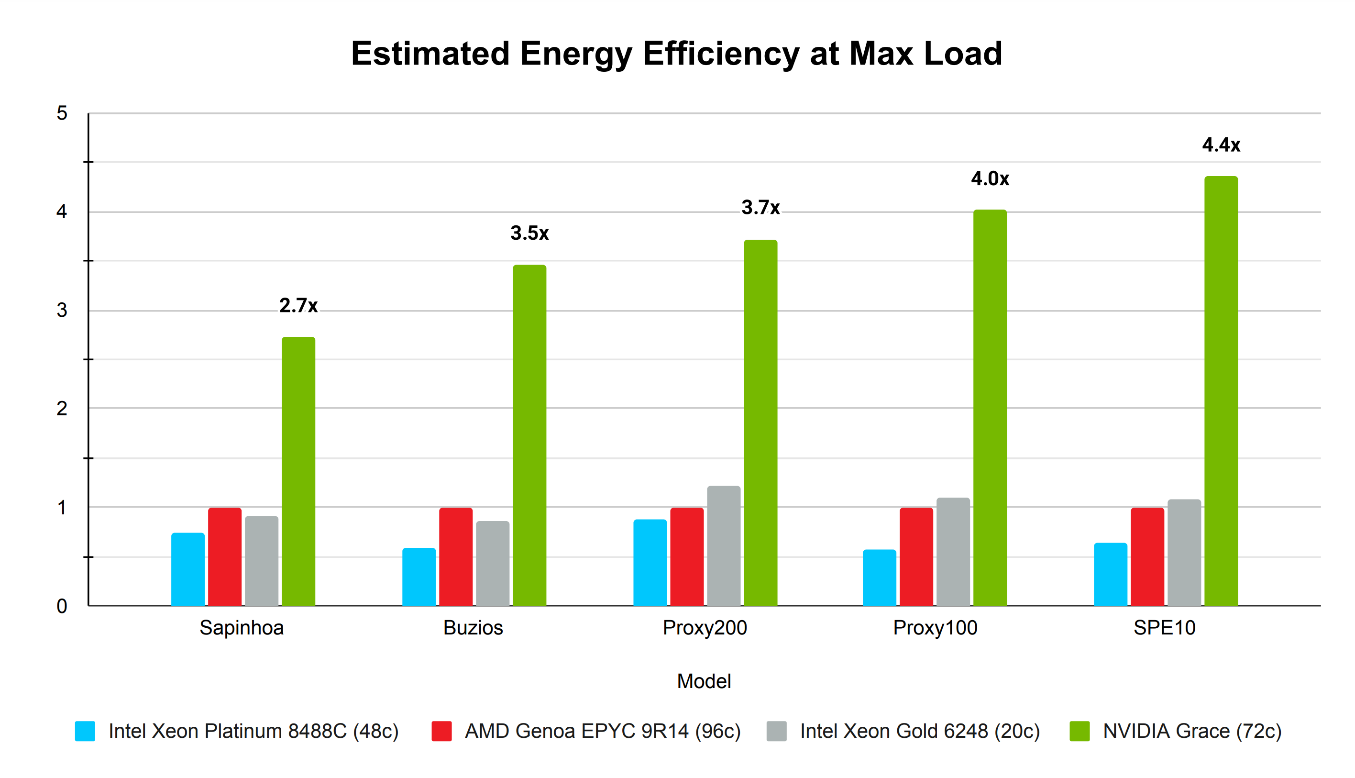
To estimate energy efficiency for the NVIDIA Grace CPU compared to on-premises CPUs, the maximum thermal design power (TDP) of each CPU was evaluated at full load with an estimated memory consumption based on processor capacity and technology generation. For the NVIDIA Grace CPU SoC, CPU memory consumption was approximately 250 W, and the speedups were reported using the AMD EPYC 9R14 as the baseline.
NVIDIA Grace demonstrated the highest estimated energy efficiency across all linear solver tests at maximum load, with up to 4.3x higher energy efficiency (Figure 5).
Conclusion
The NVIDIA Grace CPU outperformed all tested x86-based and Arm-based CPUs in TTS, scalability, and energy efficiency. This success is primarily due to the NVIDIA Grace architecture, which focuses on energy-to-compute and high application performance. Key features such as LPDDR5X memory, unified cache coherence design, SCF, and an optimized software stack based on GCC contributed to these results.
Next, Petrobras plans to port and benchmark their end-to-end geomechanical and reservoir simulators to Arm and explore the full potential of multiple NVIDIA Grace Superchips to further improve their time to solution.
To learn more about NVIDIA Grace CPU, watch the on-demand NVIDIA GTC session, Accelerating Linear Solvers on NVIDIA Grace.
Acknowledgments
This work was executed by the following engineers and analysts: Felipe Portella (Petrobras), Jose Roberto Pereira Rodrigues (Petrobras), Leonardo Gasparini (Petrobras), Vitor Aquino (CESAR), Luigi Marques da Luz (CESAR).