Vision-language models are among the advanced artificial intelligence AI systems designed to understand and process visual and textual data together. These models are known to combine the capabilities of computer vision and natural language processing tasks. The models are trained to interpret images and generate descriptions about the image, enabling a range of applications such as image captioning, visual question answering, and text-to-image synthesis. These models are trained on large datasets and powerful neural network architectures, which helps the models to learn complex relationships. This, in turn, allows the models to perform the desired tasks. This advanced system opens up possibilities for human-computer interaction and the development of intelligent systems that can communicate similarly to humans.
Large Multimodal Models (LMMs) are quite powerful however they struggle with the high-resolution input and scene understanding. To address these challenges Monkey was recently introduced. Monkey, a vision-language model, processes input images by dividing the input images into uniform patches, with each patch matching the size used in its original vision encoder training (e.g., 448×448 pixels).
This design allows the model to handle high-resolution images. Monkey employs a two-part strategy: first, it enhances visual capture through higher resolution; second, it uses a multi-level description generation method to enrich scene-object associations, creating a more comprehensive understanding of the visual data. This approach improves learning from the data by capturing detailed visuals, enhancing descriptive text generation’s effectiveness.
Monkey Architecture Overview
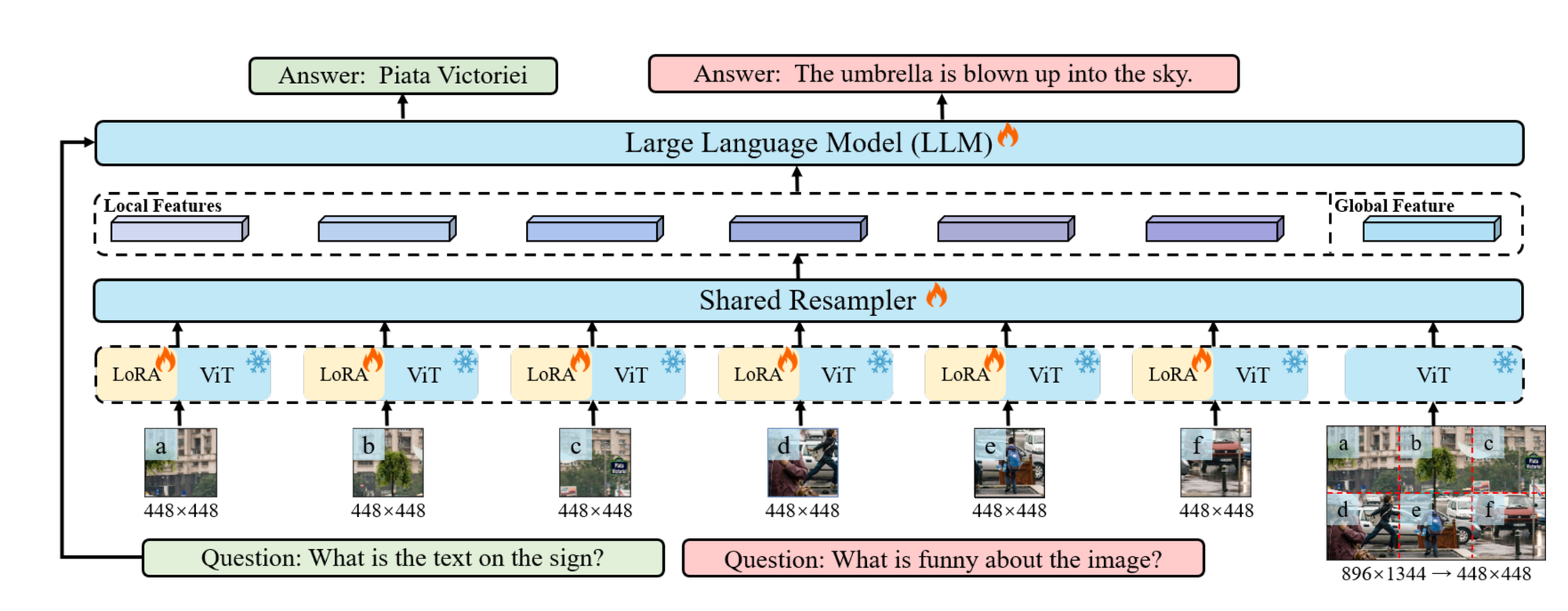
Let’s break down this approach step by step.
Image Processing with Sliding Window
- Input Image: An image (I) with dimensions (H X W X 3), where (H) and (W) are the height and width of the image, and 3 represents the color channels (RGB).
- Sliding Window: The image is divided into smaller sections using a sliding window (W) with dimensions (H_v X W_v). This process partitions the image into local sections, which allows the model to focus on specific parts of the image.
LoRA Integration
- LoRA (Low-Rank Adaptation): LoRA is employed within each shared encoder to handle the diverse visual elements present in different parts of the image. LoRA helps the encoders capture detail-sensitive features more effectively without significantly increasing the model’s parameters or computational load.
Maintaining Structural Information
- Global Image Resizing: To preserve the overall structural information of the input image, the original image is resized to dimensions ((H_v, W_v)), creating a global image. This global image maintains a holistic view while the patches provide detailed perspectives.
Processing with Visual Encoder and Resampler
- Concurrent Processing: Both the individual patches and the global image are processed through the visual encoder and resampler simultaneously.
- Visual Resampler: Inspired by the Flamingo model, the visual resampler performs two main functions:
- Summarizing Visual Information: It condenses the visual information from the image sections.
- Obtaining Higher Semantic Representations: It transforms visual information into a language feature space for better semantic understanding.
Cross-Attention Module
- Cross-Attention Mechanism: The resampler uses a cross-attention module where trainable vectors (embeddings) act as query vectors. Image features from the visual encoder serve as keys in the cross-attention operation. This allows the model to focus on important image parts while incorporating contextual information.
Balancing Detail and Holistic Understanding
- Balanced Approach: This method balances the need for detailed local analysis and a holistic global image perspective. This balance enhances the model’s performance by capturing detailed features and overall structure without substantially increasing computational resources.
This approach improves the model’s ability to understand complex images by combining local detail analysis with a global overview, leveraging advanced techniques like LoRA and cross-attention.
Few Key Points
- Resource-Efficient Input Resolution Increase: Monkey enhances input resolution in LMMs without requiring extensive pre-training. Instead of directly interpolating Vision Transformer (ViT) models to handle higher resolutions, it employs a sliding window method to divide high-resolution images into smaller patches. Each patch is processed by a static visual encoder with LoRA adjustments and a trainable visual resampler.
- Maintaining Training Data Distribution: Monkey capitalizes on encoders trained on smaller resolutions (e.g., 448×448) by resizing each patch to the supported resolution. This approach maintains the original data distribution, avoiding costly training from scratch.
- Trainable Patches Advantage: The method uses various trainable patches, enhancing resolution more effectively than traditional interpolation techniques for positional embedding.
- Automatic Multi-Level Description Generation: Monkey incorporates multiple advanced systems (e.g., BLIP2, PPOCR, GRIT, SAM, ChatGPT) to generate high-quality captions by combining insights from these generators. This approach captures a wide spectrum of visual details through layered and contextual understanding.
- Advantages of Monkey:
- High-Resolution Support: Supports resolutions up to 1344×896 without pre-training, aiding in identifying small or densely packed objects and text.
- Improved Contextual Associations: Enhances understanding of relationships among multiple targets and leverages common knowledge for better text description generation.
- Performance Enhancements: Shows competitive performance across various tasks, including Image Captioning and Visual Question Answering, demonstrating promising results compared to models like GPT-4V, especially in dense text question answering.
Overall, Monkey offers a sophisticated way to improve resolution and description generation in LMMs by using existing models more efficiently.
How can I do visual Q&A with Monkey?
To run the Monkey Model and experiment with it, we first login to Paperspace and start a notebook, or you can start up a terminal. We highly recommend using an A4000 GPU to run the model.
The NVIDIA A6000 GPU is a powerful graphics card that is known for its exceptional performance in various AI and machine learning applications, including visual question answering (VQA). With its memory and advanced Ampere architecture, the A4000 offers high throughput and efficiency, making it ideal for handling the complex computations required in VQA tasks.
!nvidia-smi
Setup
Bring this project to life
We will run the below code cells. This will clone the repository, and install the requirements.txt file.
git clone https://github.com/Yuliang-Liu/Monkey.git
cd ./Monkey
pip install -r requirements.txtWe can run the gradio demo which is fast and easy to use.
python demo.pyor follow the code along.
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "echo840/Monkey-Chat"
model = AutoModelForCausalLM.from_pretrained(checkpoint, device_map='cuda', trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
tokenizer.padding_side="left"
tokenizer.pad_token_id = tokenizer.eod_idThe code above loads the pre-trained model and tokenizer from the Hugging Face Transformers library.
“echo840/Monkey-Chat” is the name of the model checkpoint we will load. Next, we will load the model weights and configurations and map the device to CUDA-enabled GPU for faster computation.
img_path="/notebooks/quick_start_pytorch_images/image 2.png"
question = "provide a detailed caption for the image"
query = f'![]() {img_path} {question} Answer: '
input_ids = tokenizer(query, return_tensors="pt", padding='longest')
attention_mask = input_ids.attention_mask
input_ids = input_ids.input_ids
pred = model.generate(
input_ids=input_ids.cuda(),
attention_mask=attention_mask.cuda(),
do_sample=False,
num_beams=1,
max_new_tokens=512,
min_new_tokens=1,
length_penalty = 1,
num_return_sequences=1,
output_hidden_states=True,
use_cache=True,
pad_token_id=tokenizer.eod_id,
eos_token_id=tokenizer.eod_id,
)
response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip()
print(response)
{img_path} {question} Answer: '
input_ids = tokenizer(query, return_tensors="pt", padding='longest')
attention_mask = input_ids.attention_mask
input_ids = input_ids.input_ids
pred = model.generate(
input_ids=input_ids.cuda(),
attention_mask=attention_mask.cuda(),
do_sample=False,
num_beams=1,
max_new_tokens=512,
min_new_tokens=1,
length_penalty = 1,
num_return_sequences=1,
output_hidden_states=True,
use_cache=True,
pad_token_id=tokenizer.eod_id,
eos_token_id=tokenizer.eod_id,
)
response = tokenizer.decode(pred[0][input_ids.size(1):].cpu(), skip_special_tokens=True).strip()
print(response)This code will generate the detailed caption or description or any other output based on the prompt query using Monkey. We will specify the path where we have stored our image and formulating a query string that includes the image reference and the question asking for a caption. Next, the query is tokenised using the ‘tokenizer’ which converts the input texts into token IDs.
Parameters such as do_sample=False and num_beams=1 ensure deterministic output by disabling sampling. Other parameters like max_new_tokens, min_new_tokens, and length_penalty control the length and nature of the generated sequence. After generation, the output tokens are decoded back into human-readable text, skipping any special tokens, to form the final response, which is a caption describing the image. Finally, we print the generated caption.
Results
We tried the model with an extremely basic image of just a screenshot, and it does fairly well in recognizing what the image is.
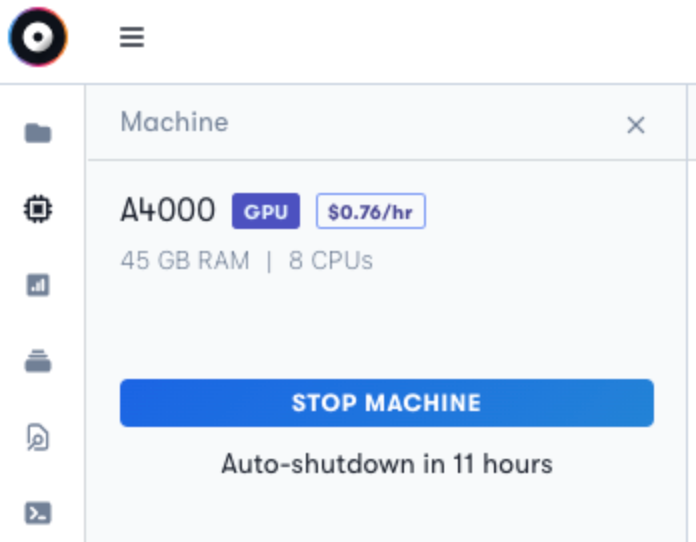
Monkey Output:- The image displays a computer interface with a blue background. The main focus is on a machine with the label “A4000” and the price “$0.76/hr”. The machine is equipped with 45 GB RAM and 8 CPUs. There are also several buttons and icons on the interface, including a blue “STOP MACHINE” button and a white “Auto-shutdown in 11 hours” button. The text “45 GB RAM” and “8 CPUs” are also visible. The overall layout suggests a user-friendly interface for managing virtual machines.

Monkey Output:- In the image, a golden retriever is captured in mid-air, leaping towards a yellow tennis ball that is suspended in the air. The dog’s body is stretched out, with its front paws reaching for the ball, and its tail is raised high in excitement. The background is a lush green lawn, providing a stark contrast to the dog’s white fur. The image is taken from a low angle, making the dog appear larger and more imposing. The dog’s focused expression and the dynamic pose suggest a moment of intense playfulness.

Prompt:- Provide a detailed caption for the image
Monkey Output:- This image is a painting of a city skyline at night. The sky is filled with swirling yellow and blue colors, creating a starry effect. In the foreground, there is a tall building with a clock on top. The painting also features a large tree with a yellow light shining on it. The overall effect is one of tranquility and beauty, reminiscent of the famous “Starry Night” painting by Vincent van Gogh.
We are quite impressed by the detailed descriptions and captions that provide even the minutest details of the image. The AI-generated caption is truly remarkable!
The below image highlights Monkey’s capabilities in various VQA tasks. Monkey analyzes questions, identifies key image elements, perceives minute text, and reasons about objects, and understands visual charts. The figure also demonstrates Monkey’s impressive captioning ability, accurately describing objects and providing summaries.

Comparison Results
In qualitative analysis, Monkey was compared with GPT4V and other LMMs on the task of generating detailed captions.

Monkey and GPT-4V identified an “Emporio Armani” store in the background, with Monkey providing additional details, such as a woman in a red coat and black pants carrying a black purse. (Image Source)
Further experiments have shown that in many cases, Monkey has demonstrated impressive performance compared to GPT4V when it comes to understanding complex text-based inquiries.

The VQA task comparison results in the below figure show that by scaling up the model size, Monkey achieves significant performance advantages in tasks involving dense text. It not only outperforms QwenVL-Chat [3], LLaVA-1.5 [29], and mPLUG-Owl2 [56] but also achieves promising results compared to GPT-4V [42]. This demonstrates the importance of scaling up model size for performance improvement in multimodal large models and validates our method’s effectiveness in enhancing their performance.

Practical Application
- Automated Image Captioning: Generate detailed descriptions for images in various domains, such as e-commerce, social media, and digital archives.
- Assistive Technologies: Aid visually impaired individuals by generating descriptive captions for images in real-time applications, such as screen readers and navigation aids.
- Interactive Chatbots: Integrate with chatbots to provide detailed visual explanations and context in customer support and virtual assistants, improving user experience in various services.
- Image-Based Search Engines: Improve image search capabilities by providing rich, context-aware descriptions that enhance search accuracy and relevance.
Conclusion
In this article, we discuss the Monkey chat vision model, the model achieved good results when tried with different images to generate captions or even to understand what is in the image. The research claims that the model outperforms various LMMs including GPT-4v. Its enhanced input resolution also significantly improves performance on document images with dense text. Leveraging advanced techniques such as sliding windows and cross-attention effectively balances local and global image perspectives. However, this method is also limited to processing the input images as a maximum of six patches due to the language model’s input length constraints, restricting further input resolution expansion.
Despite these limitations, the model shows significant promise in capturing fine details and providing insightful descriptions, particularly for document images with dense text.
We hope you enjoyed reading the article!