{kind=link}
Introduction
GPUs are described as parallel processors for their ability to execute work in parallel. Tasks are divided into smaller sub-tasks, executed simultaneously by multiple processing units, and combined to produce the final result. These processing units (threads, warps, thread blocks, cores, multiprocessors) share resources, such as memory, facilitating collaboration between them and enhancing overall GPU efficiency.
One unit in particular, warps, are a cornerstone of parallel processing. By grouping threads together into a single execution unit, warps allow for the simplification of thread management, the sharing of data and resources among threads, as well as the masking of memory latency with effective scheduling.

In this article, we will outline how warps are useful for optimizing the performance of GPU-accelerated applications. By building an intuition around warps, developers can achieve significant gains in computational speed and efficiency.
Warps Unraveled
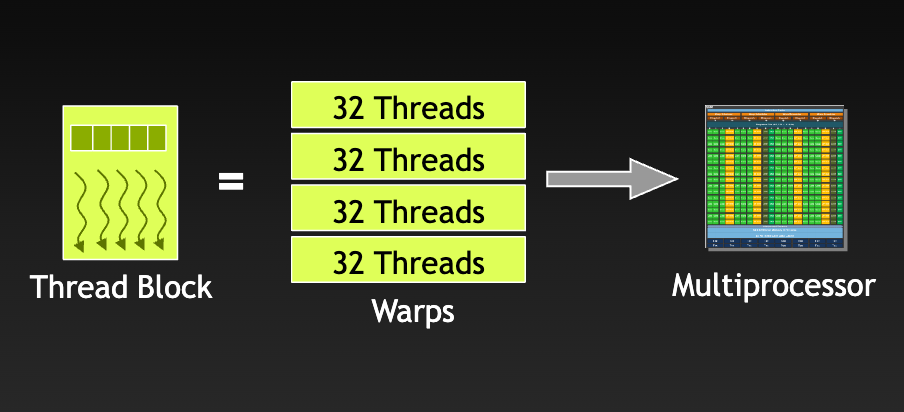
When a Streaming Multiprocessor (SM) is assigned thread blocks for execution, it subdivides the threads into warps. Modern GPU architectures typically have a warp size of 32 threads.
The number of warps in a thread block depends on the thread block size configured by the CUDA programmer. For example, if the thread block size is 96 threads and the warp size is 32 threads, the number of warps per thread block would be: 96 threads/ 32 threads per warp = 3 warps per thread block.
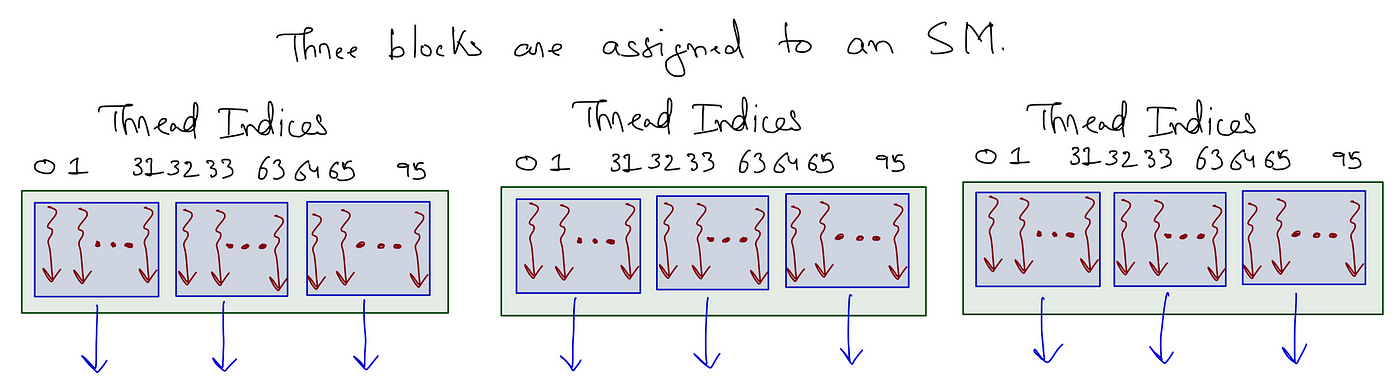
Note how, in the figure, the threads are indexed, starting at 0 and continuing between the warps in the thread block. The first warp is made of the first 32 threads (0-31), the subsequent warp has the next 32 threads (32-63), and so forth.
Now that we’ve defined warps, let’s take a step back and look at Flynn’s Taxonomy, focusing on how this categorization scheme applies to GPUs and warp-level thread management.
GPUs: SIMD or SIMT?
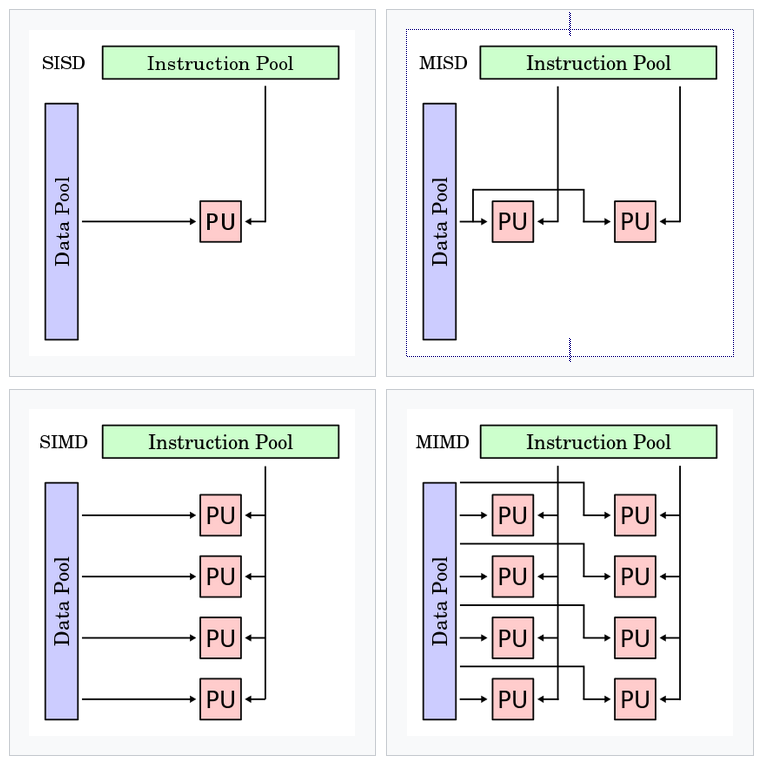
Flynn’s Taxonomy is a classification system based on a computer architecture’s number of instructions and data streams. GPUs are often described as Single Instruction Multiple Data (SIMD), meaning they simultaneously perform the same operation on multiple data operands. Single Instruction Multiple Thread (SIMT), a term coined by NVIDIA, extends upon Flynn’s Taxonomy to better describe the thread-level parallelism NVIDIA GPUs exhibit. In an SIMT architecture, multiple threads issue the same instructions to data. The combined effort of the CUDA compiler and GPU allow for threads of a warp to synchronize and execute identical instructions in unison as frequently as possible, optimizing performance.
While both SIMD and SIMT exploit data-level parallelism, they are differentiated in their approach. SIMD excels at uniform data processing, whereas SIMT offers increased flexibility as a result of its dynamic thread management and conditional execution.
Warp Scheduling Hides Latency
In the context of warps, latency is the number of clock cycles for a warp to finish executing an instruction and become available to process the next one.
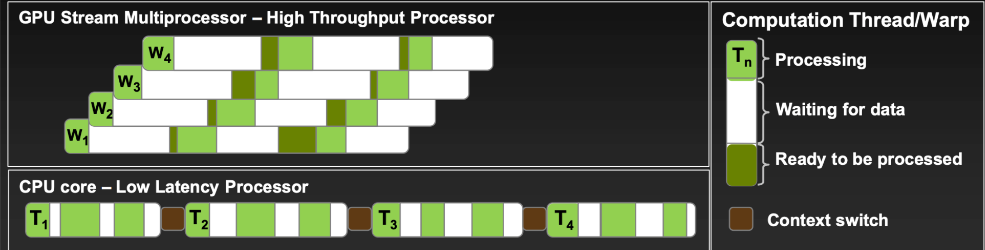
Maximum utilization is attained when all warp schedulers always have instructions to issue at every clock cycle. Thus, the number of resident warps, warps that are being executed on the SM at a given moment, directly affect utilization. In other words, there needs to be warps for warp schedulers to issue instructions to. Multiple resident warps enable the SM to switch between them, hiding latency and maximizing throughput.
Program Counters
Program counters increment each instruction cycle to retrieve the program sequence from memory, guiding the flow of the program’s execution. Notably, while threads in a warp share a common starting program address, they maintain separate program counters, allowing for autonomous execution and branching of the individual threads.
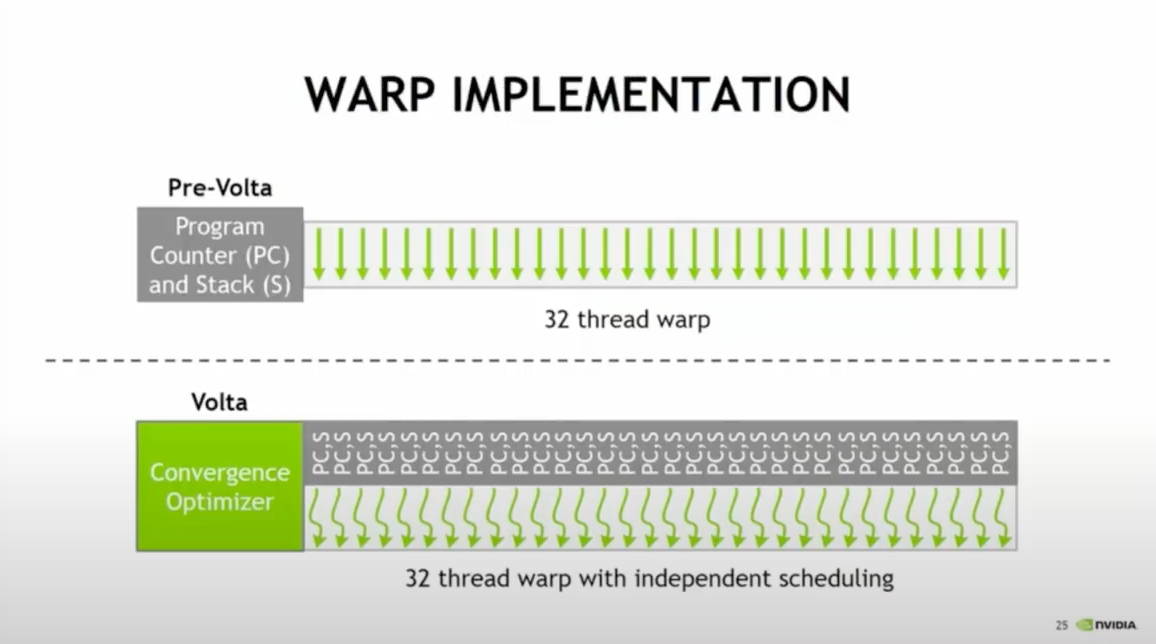
Branching
Separate program counters allow for branching, an if-then-else programming structure, where instructions are processed only if threads are active. Since optimal performance is attained when a warp’s 32 threads converge on one instruction, it is advised for programmers to write code that minimizes instances where threads within a warp take a divergent path.
Conclusion : Tying Up Loose Threads
Warps play an important role in GPU programming. This 32-thread unit leverages SIMT to increase the efficiency of parallel processing. Effective warp scheduling hides latency and maximizes throughput, allowing for the streamlined execution of complex workloads. Additionally, program counters and branching facilitate flexible thread management. Despite this flexibility, programmers are advised to avoid long sequences of diverged execution for threads in the same warp.
References
Using CUDA Warp-Level Primitives | NVIDIA Technical Blog
NVIDIA GPUs execute groups of threads known as warps in SIMT (Single Instruction, Multiple Thread) fashion. Many CUDA programs achieve high performance by taking advantage of warp execution.

CUDA C++ Programming Guide
The programming guide to the CUDA model and interface.